搜索到
14
篇与
🏠 默认分类
的结果
-
 十分钟搞定 pandas 官方网站上《10 Minutes to pandas》的一个简单的翻译,原文在这里。这篇文章是对 pandas 的一个简单的介绍,详细的介绍请参考:秘籍 。习惯上,我们会按下面格式引入所需要的包:In [1]: import pandas as pd In [2]: import numpy as np In [3]: import matplotlib.pyplot as plt一、 创建对象可以通过 数据结构入门 来查看有关该节内容的详细信息。1、可以通过传递一个list对象来创建一个Series,pandas 会默认创建整型索引:In [4]: s = pd.Series([1,3,5,np.nan,6,8]) In [5]: s Out[5]: 0 1.0 1 3.0 2 5.0 3 NaN 4 6.0 5 8.0 dtype: float642、通过传递一个 numpyarray,时间索引以及列标签来创建一个DataFrame:In [6]: dates = pd.date_range('20130101', periods=6) In [7]: dates Out[7]: DatetimeIndex(['2013-01-01', '2013-01-02', '2013-01-03', '2013-01-04', '2013-01-05', '2013-01-06'], dtype='datetime64[ns]', freq='D') In [8]: df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD')) In [9]: df Out[9]: A B C D 2013-01-01 0.469112 -0.282863 -1.509059 -1.135632 2013-01-02 1.212112 -0.173215 0.119209 -1.044236 2013-01-03 -0.861849 -2.104569 -0.494929 1.071804 2013-01-04 0.721555 -0.706771 -1.039575 0.271860 2013-01-05 -0.424972 0.567020 0.276232 -1.087401 2013-01-06 -0.673690 0.113648 -1.478427 0.5249883、通过传递一个能够被转换成类似序列结构的字典对象来创建一个DataFrame:In [10]: df2 = pd.DataFrame({ 'A' : 1., ....: 'B' : pd.Timestamp('20130102'), ....: 'C' : pd.Series(1,index=list(range(4)),dtype='float32'), ....: 'D' : np.array([3] * 4,dtype='int32'), ....: 'E' : pd.Categorical(["test","train","test","train"]), ....: 'F' : 'foo' }) ....: In [11]: df2 Out[11]: A B C D E F 0 1.0 2013-01-02 1.0 3 test foo 1 1.0 2013-01-02 1.0 3 train foo 2 1.0 2013-01-02 1.0 3 test foo 3 1.0 2013-01-02 1.0 3 train foo4、查看不同列的数据类型:In [12]: df2.dtypes Out[12]: A float64 B datetime64[ns] C float32 D int32 E category F object dtype: object5、如果你使用的是 IPython,使用 Tab 自动补全功能会自动识别所有的属性以及自定义的列,下图中是所有能够被自动识别的属性的一个子集:In [13]: df2.<TAB> df2.A df2.boxplot df2.abs df2.C df2.add df2.clip df2.add_prefix df2.clip_lower df2.add_suffix df2.clip_upper df2.align df2.columns df2.all df2.combine df2.any df2.combineAdd df2.append df2.combine_first df2.apply df2.combineMult df2.applymap df2.compound df2.as_blocks df2.consolidate df2.asfreq df2.convert_objects df2.as_matrix df2.copy df2.astype df2.corr df2.at df2.corrwith df2.at_time df2.count df2.axes df2.cov df2.B df2.cummax df2.between_time df2.cummin df2.bfill df2.cumprod df2.blocks df2.cumsum df2.bool df2.D二、 查看数据详情请参阅:基础。1、 查看DataFrame中头部和尾部的行:In [14]: df.head() Out[14]: A B C D 2013-01-01 0.469112 -0.282863 -1.509059 -1.135632 2013-01-02 1.212112 -0.173215 0.119209 -1.044236 2013-01-03 -0.861849 -2.104569 -0.494929 1.071804 2013-01-04 0.721555 -0.706771 -1.039575 0.271860 2013-01-05 -0.424972 0.567020 0.276232 -1.087401 In [15]: df.tail(3) Out[15]: A B C D 2013-01-04 0.721555 -0.706771 -1.039575 0.271860 2013-01-05 -0.424972 0.567020 0.276232 -1.087401 2013-01-06 -0.673690 0.113648 -1.478427 0.5249882、 显示索引、列和底层的 numpy 数据:In [16]: df.index Out[16]: DatetimeIndex(['2013-01-01', '2013-01-02', '2013-01-03', '2013-01-04', '2013-01-05', '2013-01-06'], dtype='datetime64[ns]', freq='D') In [17]: df.columns Out[17]: Index([u'A', u'B', u'C', u'D'], dtype='object') In [18]: df.values Out[18]: array([[ 0.4691, -0.2829, -1.5091, -1.1356], [ 1.2121, -0.1732, 0.1192, -1.0442], [-0.8618, -2.1046, -0.4949, 1.0718], [ 0.7216, -0.7068, -1.0396, 0.2719], [-0.425 , 0.567 , 0.2762, -1.0874], [-0.6737, 0.1136, -1.4784, 0.525 ]])3、 describe()函数对于数据的快速统计汇总:In [19]: df.describe() Out[19]: A B C D count 6.000000 6.000000 6.000000 6.000000 mean 0.073711 -0.431125 -0.687758 -0.233103 std 0.843157 0.922818 0.779887 0.973118 min -0.861849 -2.104569 -1.509059 -1.135632 25% -0.611510 -0.600794 -1.368714 -1.076610 50% 0.022070 -0.228039 -0.767252 -0.386188 75% 0.658444 0.041933 -0.034326 0.461706 max 1.212112 0.567020 0.276232 1.0718044、 对数据的转置:In [20]: df.T Out[20]: 2013-01-01 2013-01-02 2013-01-03 2013-01-04 2013-01-05 2013-01-06 A 0.469112 1.212112 -0.861849 0.721555 -0.424972 -0.673690 B -0.282863 -0.173215 -2.104569 -0.706771 0.567020 0.113648 C -1.509059 0.119209 -0.494929 -1.039575 0.276232 -1.478427 D -1.135632 -1.044236 1.071804 0.271860 -1.087401 0.5249885、 按轴进行排序In [21]: df.sort_index(axis=1, ascending=False) Out[21]: D C B A 2013-01-01 -1.135632 -1.509059 -0.282863 0.469112 2013-01-02 -1.044236 0.119209 -0.173215 1.212112 2013-01-03 1.071804 -0.494929 -2.104569 -0.861849 2013-01-04 0.271860 -1.039575 -0.706771 0.721555 2013-01-05 -1.087401 0.276232 0.567020 -0.424972 2013-01-06 0.524988 -1.478427 0.113648 -0.6736906、 按值进行排序In [22]: df.sort_values(by='B') Out[22]: A B C D 2013-01-03 -0.861849 -2.104569 -0.494929 1.071804 2013-01-04 0.721555 -0.706771 -1.039575 0.271860 2013-01-01 0.469112 -0.282863 -1.509059 -1.135632 2013-01-02 1.212112 -0.173215 0.119209 -1.044236 2013-01-06 -0.673690 0.113648 -1.478427 0.524988 2013-01-05 -0.424972 0.567020 0.276232 -1.087401三、 选择虽然标准的 Python/Numpy 的选择和设置表达式都能够直接派上用场,但是作为工程使用的代码,我们推荐使用经过优化的 pandas 数据访问方式: .at, .iat, .loc, .iloc 和 .ix。详情请参阅索引和选取数据 和 多重索引/高级索引。获取1、 选择一个单独的列,这将会返回一个Series,等同于df.A:In [23]: df['A'] Out[23]: 2013-01-01 0.469112 2013-01-02 1.212112 2013-01-03 -0.861849 2013-01-04 0.721555 2013-01-05 -0.424972 2013-01-06 -0.673690 Freq: D, Name: A, dtype: float642、 通过[]进行选择,这将会对行进行切片In [24]: df[0:3] Out[24]: A B C D 2013-01-01 0.469112 -0.282863 -1.509059 -1.135632 2013-01-02 1.212112 -0.173215 0.119209 -1.044236 2013-01-03 -0.861849 -2.104569 -0.494929 1.071804 In [25]: df['20130102':'20130104'] Out[25]: A B C D 2013-01-02 1.212112 -0.173215 0.119209 -1.044236 2013-01-03 -0.861849 -2.104569 -0.494929 1.071804 2013-01-04 0.721555 -0.706771 -1.039575 0.271860通过标签选择1、 使用标签来获取一个交叉的区域In [26]: df.loc[dates[0]] Out[26]: A 0.469112 B -0.282863 C -1.509059 D -1.135632 Name: 2013-01-01 00:00:00, dtype: float642、 通过标签来在多个轴上进行选择In [27]: df.loc[:,['A','B']] Out[27]: A B 2013-01-01 0.469112 -0.282863 2013-01-02 1.212112 -0.173215 2013-01-03 -0.861849 -2.104569 2013-01-04 0.721555 -0.706771 2013-01-05 -0.424972 0.567020 2013-01-06 -0.673690 0.1136483、 标签切片In [28]: df.loc['20130102':'20130104',['A','B']] Out[28]: A B 2013-01-02 1.212112 -0.173215 2013-01-03 -0.861849 -2.104569 2013-01-04 0.721555 -0.7067714、 对于返回的对象进行维度缩减In [29]: df.loc['20130102',['A','B']] Out[29]: A 1.212112 B -0.173215 Name: 2013-01-02 00:00:00, dtype: float645、 获取一个标量In [30]: df.loc[dates[0],'A'] Out[30]: 0.469112299907186286、 快速访问一个标量(与上一个方法等价)In [31]: df.at[dates[0],'A'] Out[31]: 0.46911229990718628通过位置选择1、 通过传递数值进行位置选择(选择的是行)In [32]: df.iloc[3] Out[32]: A 0.721555 B -0.706771 C -1.039575 D 0.271860 Name: 2013-01-04 00:00:00, dtype: float642、 通过数值进行切片,与 numpy/python 中的情况类似In [33]: df.iloc[3:5,0:2] Out[33]: A B 2013-01-04 0.721555 -0.706771 2013-01-05 -0.424972 0.5670203、 通过指定一个位置的列表,与 numpy/python 中的情况类似In [34]: df.iloc[[1,2,4],[0,2]] Out[34]: A C 2013-01-02 1.212112 0.119209 2013-01-03 -0.861849 -0.494929 2013-01-05 -0.424972 0.2762324、 对行进行切片In [35]: df.iloc[1:3,:] Out[35]: A B C D 2013-01-02 1.212112 -0.173215 0.119209 -1.044236 2013-01-03 -0.861849 -2.104569 -0.494929 1.0718045、 对列进行切片In [36]: df.iloc[:,1:3] Out[36]: B C 2013-01-01 -0.282863 -1.509059 2013-01-02 -0.173215 0.119209 2013-01-03 -2.104569 -0.494929 2013-01-04 -0.706771 -1.039575 2013-01-05 0.567020 0.276232 2013-01-06 0.113648 -1.4784276、 获取特定的值In [37]: df.iloc[1,1] Out[37]: -0.17321464905330858快速访问标量(等同于前一个方法):In [38]: df.iat[1,1] Out[38]: -0.17321464905330858布尔索引1、 使用一个单独列的值来选择数据:In [39]: df[df.A > 0] Out[39]: A B C D 2013-01-01 0.469112 -0.282863 -1.509059 -1.135632 2013-01-02 1.212112 -0.173215 0.119209 -1.044236 2013-01-04 0.721555 -0.706771 -1.039575 0.2718602、 使用where操作来选择数据:In [40]: df[df > 0] Out[40]: A B C D 2013-01-01 0.469112 NaN NaN NaN 2013-01-02 1.212112 NaN 0.119209 NaN 2013-01-03 NaN NaN NaN 1.071804 2013-01-04 0.721555 NaN NaN 0.271860 2013-01-05 NaN 0.567020 0.276232 NaN 2013-01-06 NaN 0.113648 NaN 0.5249883、 使用isin()方法来过滤:In [41]: df2 = df.copy() In [42]: df2['E'] = ['one', 'one','two','three','four','three'] In [43]: df2 Out[43]: A B C D E 2013-01-01 0.469112 -0.282863 -1.509059 -1.135632 one 2013-01-02 1.212112 -0.173215 0.119209 -1.044236 one 2013-01-03 -0.861849 -2.104569 -0.494929 1.071804 two 2013-01-04 0.721555 -0.706771 -1.039575 0.271860 three 2013-01-05 -0.424972 0.567020 0.276232 -1.087401 four 2013-01-06 -0.673690 0.113648 -1.478427 0.524988 three In [44]: df2[df2['E'].isin(['two','four'])] Out[44]: A B C D E 2013-01-03 -0.861849 -2.104569 -0.494929 1.071804 two 2013-01-05 -0.424972 0.567020 0.276232 -1.087401 four设置1、 设置一个新的列:In [45]: s1 = pd.Series([1,2,3,4,5,6], index=pd.date_range('20130102', periods=6)) In [46]: s1 Out[46]: 2013-01-02 1 2013-01-03 2 2013-01-04 3 2013-01-05 4 2013-01-06 5 2013-01-07 6 Freq: D, dtype: int64 In [47]: df['F'] = s12、 通过标签设置新的值:In [48]: df.at[dates[0],'A'] = 03、 通过位置设置新的值:In [49]: df.iat[0,1] = 04、 通过一个numpy数组设置一组新值:In [50]: df.loc[:,'D'] = np.array([5] * len(df))上述操作结果如下:In [51]: df Out[51]: A B C D F 2013-01-01 0.000000 0.000000 -1.509059 5 NaN 2013-01-02 1.212112 -0.173215 0.119209 5 1.0 2013-01-03 -0.861849 -2.104569 -0.494929 5 2.0 2013-01-04 0.721555 -0.706771 -1.039575 5 3.0 2013-01-05 -0.424972 0.567020 0.276232 5 4.0 2013-01-06 -0.673690 0.113648 -1.478427 5 5.05、 通过where操作来设置新的值:In [52]: df2 = df.copy() In [53]: df2[df2 > 0] = -df2 In [54]: df2 Out[54]: A B C D F 2013-01-01 0.000000 0.000000 -1.509059 -5 NaN 2013-01-02 -1.212112 -0.173215 -0.119209 -5 -1.0 2013-01-03 -0.861849 -2.104569 -0.494929 -5 -2.0 2013-01-04 -0.721555 -0.706771 -1.039575 -5 -3.0 2013-01-05 -0.424972 -0.567020 -0.276232 -5 -4.0 2013-01-06 -0.673690 -0.113648 -1.478427 -5 -5.0四、 缺失值处理在 pandas 中,使用np.nan来代替缺失值,这些值将默认不会包含在计算中,详情请参阅:缺失的数据。1、 reindex()方法可以对指定轴上的索引进行改变/增加/删除操作,这将返回原始数据的一个拷贝:In [55]: df1 = df.reindex(index=dates[0:4], columns=list(df.columns) + ['E']) In [56]: df1.loc[dates[0]:dates[1],'E'] = 1 In [57]: df1 Out[57]: A B C D F E 2013-01-01 0.000000 0.000000 -1.509059 5 NaN 1.0 2013-01-02 1.212112 -0.173215 0.119209 5 1.0 1.0 2013-01-03 -0.861849 -2.104569 -0.494929 5 2.0 NaN 2013-01-04 0.721555 -0.706771 -1.039575 5 3.0 NaN2、 去掉包含缺失值的行:In [58]: df1.dropna(how='any') Out[58]: A B C D F E 2013-01-02 1.212112 -0.173215 0.119209 5 1.0 1.03、 对缺失值进行填充:In [59]: df1.fillna(value=5) Out[59]: A B C D F E 2013-01-01 0.000000 0.000000 -1.509059 5 5.0 1.0 2013-01-02 1.212112 -0.173215 0.119209 5 1.0 1.0 2013-01-03 -0.861849 -2.104569 -0.494929 5 2.0 5.0 2013-01-04 0.721555 -0.706771 -1.039575 5 3.0 5.04、 对数据进行布尔填充:n [60]: pd.isnull(df1) Out[60]: A B C D F E 2013-01-01 False False False False True False 2013-01-02 False False False False False False 2013-01-03 False False False False False True 2013-01-04 False False False False False True五、 相关操作详情请参与 基本的二进制操作统计(相关操作通常情况下不包括缺失值)1、 执行描述性统计:In [61]: df.mean() Out[61]: A -0.004474 B -0.383981 C -0.687758 D 5.000000 F 3.000000 dtype: float642、 在其他轴上进行相同的操作:In [62]: df.mean(1) Out[62]: 2013-01-01 0.872735 2013-01-02 1.431621 2013-01-03 0.707731 2013-01-04 1.395042 2013-01-05 1.883656 2013-01-06 1.592306 Freq: D, dtype: float643、 对于拥有不同维度,需要对齐的对象进行操作。Pandas 会自动的沿着指定的维度进行广播:In [63]: s = pd.Series([1,3,5,np.nan,6,8], index=dates).shift(2) In [64]: s Out[64]: 2013-01-01 NaN 2013-01-02 NaN 2013-01-03 1.0 2013-01-04 3.0 2013-01-05 5.0 2013-01-06 NaN Freq: D, dtype: float64 In [65]: df.sub(s, axis='index') Out[65]: A B C D F 2013-01-01 NaN NaN NaN NaN NaN 2013-01-02 NaN NaN NaN NaN NaN 2013-01-03 -1.861849 -3.104569 -1.494929 4.0 1.0 2013-01-04 -2.278445 -3.706771 -4.039575 2.0 0.0 2013-01-05 -5.424972 -4.432980 -4.723768 0.0 -1.0 2013-01-06 NaN NaN NaN NaN NaNApply1、 对数据应用函数:In [66]: df.apply(np.cumsum) Out[66]: A B C D F 2013-01-01 0.000000 0.000000 -1.509059 5 NaN 2013-01-02 1.212112 -0.173215 -1.389850 10 1.0 2013-01-03 0.350263 -2.277784 -1.884779 15 3.0 2013-01-04 1.071818 -2.984555 -2.924354 20 6.0 2013-01-05 0.646846 -2.417535 -2.648122 25 10.0 2013-01-06 -0.026844 -2.303886 -4.126549 30 15.0 In [67]: df.apply(lambda x: x.max() - x.min()) Out[67]: A 2.073961 B 2.671590 C 1.785291 D 0.000000 F 4.000000 dtype: float64直方图具体请参照:直方图和离散化。In [68]: s = pd.Series(np.random.randint(0, 7, size=10)) In [69]: s Out[69]: 0 4 1 2 2 1 3 2 4 6 5 4 6 4 7 6 8 4 9 4 dtype: int64 In [70]: s.value_counts() Out[70]: 4 5 6 2 2 2 1 1 dtype: int64字符串方法Series对象在其str属性中配备了一组字符串处理方法,可以很容易的应用到数组中的每个元素,如下段代码所示。更多详情请参考:字符串向量化方法。In [71]: s = pd.Series(['A', 'B', 'C', 'Aaba', 'Baca', np.nan, 'CABA', 'dog', 'cat']) In [72]: s.str.lower() Out[72]: 0 a 1 b 2 c 3 aaba 4 baca 5 NaN 6 caba 7 dog 8 cat dtype: object六、 合并Pandas 提供了大量的方法能够轻松的对Series,DataFrame和Panel对象进行各种符合各种逻辑关系的合并操作。具体请参阅:合并。ConcatIn [73]: df = pd.DataFrame(np.random.randn(10, 4)) In [74]: df Out[74]: 0 1 2 3 0 -0.548702 1.467327 -1.015962 -0.483075 1 1.637550 -1.217659 -0.291519 -1.745505 2 -0.263952 0.991460 -0.919069 0.266046 3 -0.709661 1.669052 1.037882 -1.705775 4 -0.919854 -0.042379 1.247642 -0.009920 5 0.290213 0.495767 0.362949 1.548106 6 -1.131345 -0.089329 0.337863 -0.945867 7 -0.932132 1.956030 0.017587 -0.016692 8 -0.575247 0.254161 -1.143704 0.215897 9 1.193555 -0.077118 -0.408530 -0.862495 # break it into pieces In [75]: pieces = [df[:3], df[3:7], df[7:]] In [76]: pd.concat(pieces) Out[76]: 0 1 2 3 0 -0.548702 1.467327 -1.015962 -0.483075 1 1.637550 -1.217659 -0.291519 -1.745505 2 -0.263952 0.991460 -0.919069 0.266046 3 -0.709661 1.669052 1.037882 -1.705775 4 -0.919854 -0.042379 1.247642 -0.009920 5 0.290213 0.495767 0.362949 1.548106 6 -1.131345 -0.089329 0.337863 -0.945867 7 -0.932132 1.956030 0.017587 -0.016692 8 -0.575247 0.254161 -1.143704 0.215897 9 1.193555 -0.077118 -0.408530 -0.862495Join类似于 SQL 类型的合并,具体请参阅:数据库风格的连接In [77]: left = pd.DataFrame({'key': ['foo', 'foo'], 'lval': [1, 2]}) In [78]: right = pd.DataFrame({'key': ['foo', 'foo'], 'rval': [4, 5]}) In [79]: left Out[79]: key lval 0 foo 1 1 foo 2 In [80]: right Out[80]: key rval 0 foo 4 1 foo 5 In [81]: pd.merge(left, right, on='key') Out[81]: key lval rval 0 foo 1 4 1 foo 1 5 2 foo 2 4 3 foo 2 5另一个例子:In [82]: left = pd.DataFrame({'key': ['foo', 'bar'], 'lval': [1, 2]}) In [83]: right = pd.DataFrame({'key': ['foo', 'bar'], 'rval': [4, 5]}) In [84]: left Out[84]: key lval 0 foo 1 1 bar 2 In [85]: right Out[85]: key rval 0 foo 4 1 bar 5 In [86]: pd.merge(left, right, on='key') Out[86]: key lval rval 0 foo 1 4 1 bar 2 5Append将一行连接到一个DataFrame上,具体请参阅附加:In [87]: df = pd.DataFrame(np.random.randn(8, 4), columns=['A','B','C','D']) In [88]: df Out[88]: A B C D 0 1.346061 1.511763 1.627081 -0.990582 1 -0.441652 1.211526 0.268520 0.024580 2 -1.577585 0.396823 -0.105381 -0.532532 3 1.453749 1.208843 -0.080952 -0.264610 4 -0.727965 -0.589346 0.339969 -0.693205 5 -0.339355 0.593616 0.884345 1.591431 6 0.141809 0.220390 0.435589 0.192451 7 -0.096701 0.803351 1.715071 -0.708758 In [89]: s = df.iloc[3] In [90]: df.append(s, ignore_index=True) Out[90]: A B C D 0 1.346061 1.511763 1.627081 -0.990582 1 -0.441652 1.211526 0.268520 0.024580 2 -1.577585 0.396823 -0.105381 -0.532532 3 1.453749 1.208843 -0.080952 -0.264610 4 -0.727965 -0.589346 0.339969 -0.693205 5 -0.339355 0.593616 0.884345 1.591431 6 0.141809 0.220390 0.435589 0.192451 7 -0.096701 0.803351 1.715071 -0.708758 8 1.453749 1.208843 -0.080952 -0.264610七、 分组对于”group by”操作,我们通常是指以下一个或多个操作步骤:(Splitting)按照一些规则将数据分为不同的组;(Applying)对于每组数据分别执行一个函数;(Combining)将结果组合到一个数据结构中;详情请参阅:Grouping sectionIn [91]: df = pd.DataFrame({'A' : ['foo', 'bar', 'foo', 'bar', ....: 'foo', 'bar', 'foo', 'foo'], ....: 'B' : ['one', 'one', 'two', 'three', ....: 'two', 'two', 'one', 'three'], ....: 'C' : np.random.randn(8), ....: 'D' : np.random.randn(8)}) ....: In [92]: df Out[92]: A B C D 0 foo one -1.202872 -0.055224 1 bar one -1.814470 2.395985 2 foo two 1.018601 1.552825 3 bar three -0.595447 0.166599 4 foo two 1.395433 0.047609 5 bar two -0.392670 -0.136473 6 foo one 0.007207 -0.561757 7 foo three 1.928123 -1.6230331、 分组并对每个分组执行sum函数:In [93]: df.groupby('A').sum() Out[93]: C D A bar -2.802588 2.42611 foo 3.146492 -0.639582、 通过多个列进行分组形成一个层次索引,然后执行函数:In [94]: df.groupby(['A','B']).sum() Out[94]: C D A B bar one -1.814470 2.395985 three -0.595447 0.166599 two -0.392670 -0.136473 foo one -1.195665 -0.616981 three 1.928123 -1.623033 two 2.414034 1.600434八、 改变形状详情请参阅 层次索引 和 改变形状。StackIn [95]: tuples = list(zip(*[['bar', 'bar', 'baz', 'baz', ....: 'foo', 'foo', 'qux', 'qux'], ....: ['one', 'two', 'one', 'two', ....: 'one', 'two', 'one', 'two']])) ....: In [96]: index = pd.MultiIndex.from_tuples(tuples, names=['first', 'second']) In [97]: df = pd.DataFrame(np.random.randn(8, 2), index=index, columns=['A', 'B']) In [98]: df2 = df[:4] In [99]: df2 Out[99]: A B first second bar one 0.029399 -0.542108 two 0.282696 -0.087302 baz one -1.575170 1.771208 two 0.816482 1.100230In [100]: stacked = df2.stack() In [101]: stacked Out[101]: first second bar one A 0.029399 B -0.542108 two A 0.282696 B -0.087302 baz one A -1.575170 B 1.771208 two A 0.816482 B 1.100230 dtype: float64In [102]: stacked.unstack() Out[102]: A B first second bar one 0.029399 -0.542108 two 0.282696 -0.087302 baz one -1.575170 1.771208 two 0.816482 1.100230 In [103]: stacked.unstack(1) Out[103]: second one two first bar A 0.029399 0.282696 B -0.542108 -0.087302 baz A -1.575170 0.816482 B 1.771208 1.100230 In [104]: stacked.unstack(0) Out[104]: first bar baz second one A 0.029399 -1.575170 B -0.542108 1.771208 two A 0.282696 0.816482 B -0.087302 1.100230数据透视表详情请参阅:数据透视表.In [105]: df = pd.DataFrame({'A' : ['one', 'one', 'two', 'three'] * 3, .....: 'B' : ['A', 'B', 'C'] * 4, .....: 'C' : ['foo', 'foo', 'foo', 'bar', 'bar', 'bar'] * 2, .....: 'D' : np.random.randn(12), .....: 'E' : np.random.randn(12)}) .....: In [106]: df Out[106]: A B C D E 0 one A foo 1.418757 -0.179666 1 one B foo -1.879024 1.291836 2 two C foo 0.536826 -0.009614 3 three A bar 1.006160 0.392149 4 one B bar -0.029716 0.264599 5 one C bar -1.146178 -0.057409 6 two A foo 0.100900 -1.425638 7 three B foo -1.035018 1.024098 8 one C foo 0.314665 -0.106062 9 one A bar -0.773723 1.824375 10 two B bar -1.170653 0.595974 11 three C bar 0.648740 1.167115可以从这个数据中轻松的生成数据透视表:In [107]: pd.pivot_table(df, values='D', index=['A', 'B'], columns=['C']) Out[107]: C bar foo A B one A -0.773723 1.418757 B -0.029716 -1.879024 C -1.146178 0.314665 three A 1.006160 NaN B NaN -1.035018 C 0.648740 NaN two A NaN 0.100900 B -1.170653 NaN C NaN 0.536826九、 时间序列Pandas 在对频率转换进行重新采样时拥有简单、强大且高效的功能(如将按秒采样的数据转换为按5分钟为单位进行采样的数据)。这种操作在金融领域非常常见。具体参考:时间序列。In [108]: rng = pd.date_range('1/1/2012', periods=100, freq='S') In [109]: ts = pd.Series(np.random.randint(0, 500, len(rng)), index=rng) In [110]: ts.resample('5Min').sum() Out[110]: 2012-01-01 25083 Freq: 5T, dtype: int641、 时区表示:In [111]: rng = pd.date_range('3/6/2012 00:00', periods=5, freq='D') In [112]: ts = pd.Series(np.random.randn(len(rng)), rng) In [113]: ts Out[113]: 2012-03-06 0.464000 2012-03-07 0.227371 2012-03-08 -0.496922 2012-03-09 0.306389 2012-03-10 -2.290613 Freq: D, dtype: float64 In [114]: ts_utc = ts.tz_localize('UTC') In [115]: ts_utc Out[115]: 2012-03-06 00:00:00+00:00 0.464000 2012-03-07 00:00:00+00:00 0.227371 2012-03-08 00:00:00+00:00 -0.496922 2012-03-09 00:00:00+00:00 0.306389 2012-03-10 00:00:00+00:00 -2.290613 Freq: D, dtype: float642、 时区转换:In [116]: ts_utc.tz_convert('US/Eastern') Out[116]: 2012-03-05 19:00:00-05:00 0.464000 2012-03-06 19:00:00-05:00 0.227371 2012-03-07 19:00:00-05:00 -0.496922 2012-03-08 19:00:00-05:00 0.306389 2012-03-09 19:00:00-05:00 -2.290613 Freq: D, dtype: float643、 时间跨度转换:In [117]: rng = pd.date_range('1/1/2012', periods=5, freq='M') In [118]: ts = pd.Series(np.random.randn(len(rng)), index=rng) In [119]: ts Out[119]: 2012-01-31 -1.134623 2012-02-29 -1.561819 2012-03-31 -0.260838 2012-04-30 0.281957 2012-05-31 1.523962 Freq: M, dtype: float64 In [120]: ps = ts.to_period() In [121]: ps Out[121]: 2012-01 -1.134623 2012-02 -1.561819 2012-03 -0.260838 2012-04 0.281957 2012-05 1.523962 Freq: M, dtype: float64 In [122]: ps.to_timestamp() Out[122]: 2012-01-01 -1.134623 2012-02-01 -1.561819 2012-03-01 -0.260838 2012-04-01 0.281957 2012-05-01 1.523962 Freq: MS, dtype: float644、 时期和时间戳之间的转换使得可以使用一些方便的算术函数。In [123]: prng = pd.period_range('1990Q1', '2000Q4', freq='Q-NOV') In [124]: ts = pd.Series(np.random.randn(len(prng)), prng) In [125]: ts.index = (prng.asfreq('M', 'e') + 1).asfreq('H', 's') + 9 In [126]: ts.head() Out[126]: 1990-03-01 09:00 -0.902937 1990-06-01 09:00 0.068159 1990-09-01 09:00 -0.057873 1990-12-01 09:00 -0.368204 1991-03-01 09:00 -1.144073 Freq: H, dtype: float64十、 Categorical从 0.15 版本开始,pandas 可以在DataFrame中支持 Categorical 类型的数据,详细 介绍参看:Categorical 简介和API documentation。In [127]: df = pd.DataFrame({"id":[1,2,3,4,5,6], "raw_grade":['a', 'b', 'b', 'a', 'a', 'e']})1、 将原始的grade转换为 Categorical 数据类型:In [128]: df["grade"] = df["raw_grade"].astype("category") In [129]: df["grade"] Out[129]: 0 a 1 b 2 b 3 a 4 a 5 e Name: grade, dtype: category Categories (3, object): [a, b, e]2、 将 Categorical 类型数据重命名为更有意义的名称:In [130]: df["grade"].cat.categories = ["very good", "good", "very bad"]3、 对类别进行重新排序,增加缺失的类别:In [131]: df["grade"] = df["grade"].cat.set_categories(["very bad", "bad", "medium", "good", "very good"]) In [132]: df["grade"] Out[132]: 0 very good 1 good 2 good 3 very good 4 very good 5 very bad Name: grade, dtype: category Categories (5, object): [very bad, bad, medium, good, very good]4、 排序是按照 Categorical 的顺序进行的而不是按照字典顺序进行:In [133]: df.sort_values(by="grade") Out[133]: id raw_grade grade 5 6 e very bad 1 2 b good 2 3 b good 0 1 a very good 3 4 a very good 4 5 a very good5、 对 Categorical 列进行排序时存在空的类别:In [134]: df.groupby("grade").size() Out[134]: grade very bad 1 bad 0 medium 0 good 2 very good 3 dtype: int64十一、 画图具体文档参看:绘图文档。In [135]: ts = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2000', periods=1000)) In [136]: ts = ts.cumsum() In [137]: ts.plot() Out[137]: <matplotlib.axes._subplots.AxesSubplot at 0x7ff2ab2af550>对于DataFrame来说,plot是一种将所有列及其标签进行绘制的简便方法:In [138]: df = pd.DataFrame(np.random.randn(1000, 4), index=ts.index, .....: columns=['A', 'B', 'C', 'D']) .....: In [139]: df = df.cumsum() In [140]: plt.figure(); df.plot(); plt.legend(loc='best') Out[140]: <matplotlib.legend.Legend at 0x7ff29c8163d0>十二、 导入和保存数据CSV参考:写入 CSV 文件。1、 写入 csv 文件:In [141]: df.to_csv('foo.csv')2、 从 csv 文件中读取:In [142]: pd.read_csv('foo.csv') Out[142]: Unnamed: 0 A B C D 0 2000-01-01 0.266457 -0.399641 -0.219582 1.186860 1 2000-01-02 -1.170732 -0.345873 1.653061 -0.282953 2 2000-01-03 -1.734933 0.530468 2.060811 -0.515536 3 2000-01-04 -1.555121 1.452620 0.239859 -1.156896 4 2000-01-05 0.578117 0.511371 0.103552 -2.428202 5 2000-01-06 0.478344 0.449933 -0.741620 -1.962409 6 2000-01-07 1.235339 -0.091757 -1.543861 -1.084753 .. ... ... ... ... ... 993 2002-09-20 -10.628548 -9.153563 -7.883146 28.313940 994 2002-09-21 -10.390377 -8.727491 -6.399645 30.914107 995 2002-09-22 -8.985362 -8.485624 -4.669462 31.367740 996 2002-09-23 -9.558560 -8.781216 -4.499815 30.518439 997 2002-09-24 -9.902058 -9.340490 -4.386639 30.105593 998 2002-09-25 -10.216020 -9.480682 -3.933802 29.758560 999 2002-09-26 -11.856774 -10.671012 -3.216025 29.369368 [1000 rows x 5 columns]HDF5参考:HDF5 存储1、 写入 HDF5 存储:In [143]: df.to_hdf('foo.h5','df')2、 从 HDF5 存储中读取:In [144]: pd.read_hdf('foo.h5','df') Out[144]: A B C D 2000-01-01 0.266457 -0.399641 -0.219582 1.186860 2000-01-02 -1.170732 -0.345873 1.653061 -0.282953 2000-01-03 -1.734933 0.530468 2.060811 -0.515536 2000-01-04 -1.555121 1.452620 0.239859 -1.156896 2000-01-05 0.578117 0.511371 0.103552 -2.428202 2000-01-06 0.478344 0.449933 -0.741620 -1.962409 2000-01-07 1.235339 -0.091757 -1.543861 -1.084753 ... ... ... ... ... 2002-09-20 -10.628548 -9.153563 -7.883146 28.313940 2002-09-21 -10.390377 -8.727491 -6.399645 30.914107 2002-09-22 -8.985362 -8.485624 -4.669462 31.367740 2002-09-23 -9.558560 -8.781216 -4.499815 30.518439 2002-09-24 -9.902058 -9.340490 -4.386639 30.105593 2002-09-25 -10.216020 -9.480682 -3.933802 29.758560 2002-09-26 -11.856774 -10.671012 -3.216025 29.369368 [1000 rows x 4 columns]Excel参考:MS Excel1、 写入excel文件:In [145]: df.to_excel('foo.xlsx', sheet_name='Sheet1')2、 从excel文件中读取:In [146]: pd.read_excel('foo.xlsx', 'Sheet1', index_col=None, na_values=['NA']) Out[146]: A B C D 2000-01-01 0.266457 -0.399641 -0.219582 1.186860 2000-01-02 -1.170732 -0.345873 1.653061 -0.282953 2000-01-03 -1.734933 0.530468 2.060811 -0.515536 2000-01-04 -1.555121 1.452620 0.239859 -1.156896 2000-01-05 0.578117 0.511371 0.103552 -2.428202 2000-01-06 0.478344 0.449933 -0.741620 -1.962409 2000-01-07 1.235339 -0.091757 -1.543861 -1.084753 ... ... ... ... ... 2002-09-20 -10.628548 -9.153563 -7.883146 28.313940 2002-09-21 -10.390377 -8.727491 -6.399645 30.914107 2002-09-22 -8.985362 -8.485624 -4.669462 31.367740 2002-09-23 -9.558560 -8.781216 -4.499815 30.518439 2002-09-24 -9.902058 -9.340490 -4.386639 30.105593 2002-09-25 -10.216020 -9.480682 -3.933802 29.758560 2002-09-26 -11.856774 -10.671012 -3.216025 29.369368 [1000 rows x 4 columns]十三、陷阱如果你尝试某个操作并且看到如下异常:>>> if pd.Series([False, True, False]): print("I was true") Traceback ... ValueError: The truth value of an array is ambiguous. Use a.empty, a.any() or a.all().解释及处理方式请见比较。同时请见陷阱。
十分钟搞定 pandas 官方网站上《10 Minutes to pandas》的一个简单的翻译,原文在这里。这篇文章是对 pandas 的一个简单的介绍,详细的介绍请参考:秘籍 。习惯上,我们会按下面格式引入所需要的包:In [1]: import pandas as pd In [2]: import numpy as np In [3]: import matplotlib.pyplot as plt一、 创建对象可以通过 数据结构入门 来查看有关该节内容的详细信息。1、可以通过传递一个list对象来创建一个Series,pandas 会默认创建整型索引:In [4]: s = pd.Series([1,3,5,np.nan,6,8]) In [5]: s Out[5]: 0 1.0 1 3.0 2 5.0 3 NaN 4 6.0 5 8.0 dtype: float642、通过传递一个 numpyarray,时间索引以及列标签来创建一个DataFrame:In [6]: dates = pd.date_range('20130101', periods=6) In [7]: dates Out[7]: DatetimeIndex(['2013-01-01', '2013-01-02', '2013-01-03', '2013-01-04', '2013-01-05', '2013-01-06'], dtype='datetime64[ns]', freq='D') In [8]: df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD')) In [9]: df Out[9]: A B C D 2013-01-01 0.469112 -0.282863 -1.509059 -1.135632 2013-01-02 1.212112 -0.173215 0.119209 -1.044236 2013-01-03 -0.861849 -2.104569 -0.494929 1.071804 2013-01-04 0.721555 -0.706771 -1.039575 0.271860 2013-01-05 -0.424972 0.567020 0.276232 -1.087401 2013-01-06 -0.673690 0.113648 -1.478427 0.5249883、通过传递一个能够被转换成类似序列结构的字典对象来创建一个DataFrame:In [10]: df2 = pd.DataFrame({ 'A' : 1., ....: 'B' : pd.Timestamp('20130102'), ....: 'C' : pd.Series(1,index=list(range(4)),dtype='float32'), ....: 'D' : np.array([3] * 4,dtype='int32'), ....: 'E' : pd.Categorical(["test","train","test","train"]), ....: 'F' : 'foo' }) ....: In [11]: df2 Out[11]: A B C D E F 0 1.0 2013-01-02 1.0 3 test foo 1 1.0 2013-01-02 1.0 3 train foo 2 1.0 2013-01-02 1.0 3 test foo 3 1.0 2013-01-02 1.0 3 train foo4、查看不同列的数据类型:In [12]: df2.dtypes Out[12]: A float64 B datetime64[ns] C float32 D int32 E category F object dtype: object5、如果你使用的是 IPython,使用 Tab 自动补全功能会自动识别所有的属性以及自定义的列,下图中是所有能够被自动识别的属性的一个子集:In [13]: df2.<TAB> df2.A df2.boxplot df2.abs df2.C df2.add df2.clip df2.add_prefix df2.clip_lower df2.add_suffix df2.clip_upper df2.align df2.columns df2.all df2.combine df2.any df2.combineAdd df2.append df2.combine_first df2.apply df2.combineMult df2.applymap df2.compound df2.as_blocks df2.consolidate df2.asfreq df2.convert_objects df2.as_matrix df2.copy df2.astype df2.corr df2.at df2.corrwith df2.at_time df2.count df2.axes df2.cov df2.B df2.cummax df2.between_time df2.cummin df2.bfill df2.cumprod df2.blocks df2.cumsum df2.bool df2.D二、 查看数据详情请参阅:基础。1、 查看DataFrame中头部和尾部的行:In [14]: df.head() Out[14]: A B C D 2013-01-01 0.469112 -0.282863 -1.509059 -1.135632 2013-01-02 1.212112 -0.173215 0.119209 -1.044236 2013-01-03 -0.861849 -2.104569 -0.494929 1.071804 2013-01-04 0.721555 -0.706771 -1.039575 0.271860 2013-01-05 -0.424972 0.567020 0.276232 -1.087401 In [15]: df.tail(3) Out[15]: A B C D 2013-01-04 0.721555 -0.706771 -1.039575 0.271860 2013-01-05 -0.424972 0.567020 0.276232 -1.087401 2013-01-06 -0.673690 0.113648 -1.478427 0.5249882、 显示索引、列和底层的 numpy 数据:In [16]: df.index Out[16]: DatetimeIndex(['2013-01-01', '2013-01-02', '2013-01-03', '2013-01-04', '2013-01-05', '2013-01-06'], dtype='datetime64[ns]', freq='D') In [17]: df.columns Out[17]: Index([u'A', u'B', u'C', u'D'], dtype='object') In [18]: df.values Out[18]: array([[ 0.4691, -0.2829, -1.5091, -1.1356], [ 1.2121, -0.1732, 0.1192, -1.0442], [-0.8618, -2.1046, -0.4949, 1.0718], [ 0.7216, -0.7068, -1.0396, 0.2719], [-0.425 , 0.567 , 0.2762, -1.0874], [-0.6737, 0.1136, -1.4784, 0.525 ]])3、 describe()函数对于数据的快速统计汇总:In [19]: df.describe() Out[19]: A B C D count 6.000000 6.000000 6.000000 6.000000 mean 0.073711 -0.431125 -0.687758 -0.233103 std 0.843157 0.922818 0.779887 0.973118 min -0.861849 -2.104569 -1.509059 -1.135632 25% -0.611510 -0.600794 -1.368714 -1.076610 50% 0.022070 -0.228039 -0.767252 -0.386188 75% 0.658444 0.041933 -0.034326 0.461706 max 1.212112 0.567020 0.276232 1.0718044、 对数据的转置:In [20]: df.T Out[20]: 2013-01-01 2013-01-02 2013-01-03 2013-01-04 2013-01-05 2013-01-06 A 0.469112 1.212112 -0.861849 0.721555 -0.424972 -0.673690 B -0.282863 -0.173215 -2.104569 -0.706771 0.567020 0.113648 C -1.509059 0.119209 -0.494929 -1.039575 0.276232 -1.478427 D -1.135632 -1.044236 1.071804 0.271860 -1.087401 0.5249885、 按轴进行排序In [21]: df.sort_index(axis=1, ascending=False) Out[21]: D C B A 2013-01-01 -1.135632 -1.509059 -0.282863 0.469112 2013-01-02 -1.044236 0.119209 -0.173215 1.212112 2013-01-03 1.071804 -0.494929 -2.104569 -0.861849 2013-01-04 0.271860 -1.039575 -0.706771 0.721555 2013-01-05 -1.087401 0.276232 0.567020 -0.424972 2013-01-06 0.524988 -1.478427 0.113648 -0.6736906、 按值进行排序In [22]: df.sort_values(by='B') Out[22]: A B C D 2013-01-03 -0.861849 -2.104569 -0.494929 1.071804 2013-01-04 0.721555 -0.706771 -1.039575 0.271860 2013-01-01 0.469112 -0.282863 -1.509059 -1.135632 2013-01-02 1.212112 -0.173215 0.119209 -1.044236 2013-01-06 -0.673690 0.113648 -1.478427 0.524988 2013-01-05 -0.424972 0.567020 0.276232 -1.087401三、 选择虽然标准的 Python/Numpy 的选择和设置表达式都能够直接派上用场,但是作为工程使用的代码,我们推荐使用经过优化的 pandas 数据访问方式: .at, .iat, .loc, .iloc 和 .ix。详情请参阅索引和选取数据 和 多重索引/高级索引。获取1、 选择一个单独的列,这将会返回一个Series,等同于df.A:In [23]: df['A'] Out[23]: 2013-01-01 0.469112 2013-01-02 1.212112 2013-01-03 -0.861849 2013-01-04 0.721555 2013-01-05 -0.424972 2013-01-06 -0.673690 Freq: D, Name: A, dtype: float642、 通过[]进行选择,这将会对行进行切片In [24]: df[0:3] Out[24]: A B C D 2013-01-01 0.469112 -0.282863 -1.509059 -1.135632 2013-01-02 1.212112 -0.173215 0.119209 -1.044236 2013-01-03 -0.861849 -2.104569 -0.494929 1.071804 In [25]: df['20130102':'20130104'] Out[25]: A B C D 2013-01-02 1.212112 -0.173215 0.119209 -1.044236 2013-01-03 -0.861849 -2.104569 -0.494929 1.071804 2013-01-04 0.721555 -0.706771 -1.039575 0.271860通过标签选择1、 使用标签来获取一个交叉的区域In [26]: df.loc[dates[0]] Out[26]: A 0.469112 B -0.282863 C -1.509059 D -1.135632 Name: 2013-01-01 00:00:00, dtype: float642、 通过标签来在多个轴上进行选择In [27]: df.loc[:,['A','B']] Out[27]: A B 2013-01-01 0.469112 -0.282863 2013-01-02 1.212112 -0.173215 2013-01-03 -0.861849 -2.104569 2013-01-04 0.721555 -0.706771 2013-01-05 -0.424972 0.567020 2013-01-06 -0.673690 0.1136483、 标签切片In [28]: df.loc['20130102':'20130104',['A','B']] Out[28]: A B 2013-01-02 1.212112 -0.173215 2013-01-03 -0.861849 -2.104569 2013-01-04 0.721555 -0.7067714、 对于返回的对象进行维度缩减In [29]: df.loc['20130102',['A','B']] Out[29]: A 1.212112 B -0.173215 Name: 2013-01-02 00:00:00, dtype: float645、 获取一个标量In [30]: df.loc[dates[0],'A'] Out[30]: 0.469112299907186286、 快速访问一个标量(与上一个方法等价)In [31]: df.at[dates[0],'A'] Out[31]: 0.46911229990718628通过位置选择1、 通过传递数值进行位置选择(选择的是行)In [32]: df.iloc[3] Out[32]: A 0.721555 B -0.706771 C -1.039575 D 0.271860 Name: 2013-01-04 00:00:00, dtype: float642、 通过数值进行切片,与 numpy/python 中的情况类似In [33]: df.iloc[3:5,0:2] Out[33]: A B 2013-01-04 0.721555 -0.706771 2013-01-05 -0.424972 0.5670203、 通过指定一个位置的列表,与 numpy/python 中的情况类似In [34]: df.iloc[[1,2,4],[0,2]] Out[34]: A C 2013-01-02 1.212112 0.119209 2013-01-03 -0.861849 -0.494929 2013-01-05 -0.424972 0.2762324、 对行进行切片In [35]: df.iloc[1:3,:] Out[35]: A B C D 2013-01-02 1.212112 -0.173215 0.119209 -1.044236 2013-01-03 -0.861849 -2.104569 -0.494929 1.0718045、 对列进行切片In [36]: df.iloc[:,1:3] Out[36]: B C 2013-01-01 -0.282863 -1.509059 2013-01-02 -0.173215 0.119209 2013-01-03 -2.104569 -0.494929 2013-01-04 -0.706771 -1.039575 2013-01-05 0.567020 0.276232 2013-01-06 0.113648 -1.4784276、 获取特定的值In [37]: df.iloc[1,1] Out[37]: -0.17321464905330858快速访问标量(等同于前一个方法):In [38]: df.iat[1,1] Out[38]: -0.17321464905330858布尔索引1、 使用一个单独列的值来选择数据:In [39]: df[df.A > 0] Out[39]: A B C D 2013-01-01 0.469112 -0.282863 -1.509059 -1.135632 2013-01-02 1.212112 -0.173215 0.119209 -1.044236 2013-01-04 0.721555 -0.706771 -1.039575 0.2718602、 使用where操作来选择数据:In [40]: df[df > 0] Out[40]: A B C D 2013-01-01 0.469112 NaN NaN NaN 2013-01-02 1.212112 NaN 0.119209 NaN 2013-01-03 NaN NaN NaN 1.071804 2013-01-04 0.721555 NaN NaN 0.271860 2013-01-05 NaN 0.567020 0.276232 NaN 2013-01-06 NaN 0.113648 NaN 0.5249883、 使用isin()方法来过滤:In [41]: df2 = df.copy() In [42]: df2['E'] = ['one', 'one','two','three','four','three'] In [43]: df2 Out[43]: A B C D E 2013-01-01 0.469112 -0.282863 -1.509059 -1.135632 one 2013-01-02 1.212112 -0.173215 0.119209 -1.044236 one 2013-01-03 -0.861849 -2.104569 -0.494929 1.071804 two 2013-01-04 0.721555 -0.706771 -1.039575 0.271860 three 2013-01-05 -0.424972 0.567020 0.276232 -1.087401 four 2013-01-06 -0.673690 0.113648 -1.478427 0.524988 three In [44]: df2[df2['E'].isin(['two','four'])] Out[44]: A B C D E 2013-01-03 -0.861849 -2.104569 -0.494929 1.071804 two 2013-01-05 -0.424972 0.567020 0.276232 -1.087401 four设置1、 设置一个新的列:In [45]: s1 = pd.Series([1,2,3,4,5,6], index=pd.date_range('20130102', periods=6)) In [46]: s1 Out[46]: 2013-01-02 1 2013-01-03 2 2013-01-04 3 2013-01-05 4 2013-01-06 5 2013-01-07 6 Freq: D, dtype: int64 In [47]: df['F'] = s12、 通过标签设置新的值:In [48]: df.at[dates[0],'A'] = 03、 通过位置设置新的值:In [49]: df.iat[0,1] = 04、 通过一个numpy数组设置一组新值:In [50]: df.loc[:,'D'] = np.array([5] * len(df))上述操作结果如下:In [51]: df Out[51]: A B C D F 2013-01-01 0.000000 0.000000 -1.509059 5 NaN 2013-01-02 1.212112 -0.173215 0.119209 5 1.0 2013-01-03 -0.861849 -2.104569 -0.494929 5 2.0 2013-01-04 0.721555 -0.706771 -1.039575 5 3.0 2013-01-05 -0.424972 0.567020 0.276232 5 4.0 2013-01-06 -0.673690 0.113648 -1.478427 5 5.05、 通过where操作来设置新的值:In [52]: df2 = df.copy() In [53]: df2[df2 > 0] = -df2 In [54]: df2 Out[54]: A B C D F 2013-01-01 0.000000 0.000000 -1.509059 -5 NaN 2013-01-02 -1.212112 -0.173215 -0.119209 -5 -1.0 2013-01-03 -0.861849 -2.104569 -0.494929 -5 -2.0 2013-01-04 -0.721555 -0.706771 -1.039575 -5 -3.0 2013-01-05 -0.424972 -0.567020 -0.276232 -5 -4.0 2013-01-06 -0.673690 -0.113648 -1.478427 -5 -5.0四、 缺失值处理在 pandas 中,使用np.nan来代替缺失值,这些值将默认不会包含在计算中,详情请参阅:缺失的数据。1、 reindex()方法可以对指定轴上的索引进行改变/增加/删除操作,这将返回原始数据的一个拷贝:In [55]: df1 = df.reindex(index=dates[0:4], columns=list(df.columns) + ['E']) In [56]: df1.loc[dates[0]:dates[1],'E'] = 1 In [57]: df1 Out[57]: A B C D F E 2013-01-01 0.000000 0.000000 -1.509059 5 NaN 1.0 2013-01-02 1.212112 -0.173215 0.119209 5 1.0 1.0 2013-01-03 -0.861849 -2.104569 -0.494929 5 2.0 NaN 2013-01-04 0.721555 -0.706771 -1.039575 5 3.0 NaN2、 去掉包含缺失值的行:In [58]: df1.dropna(how='any') Out[58]: A B C D F E 2013-01-02 1.212112 -0.173215 0.119209 5 1.0 1.03、 对缺失值进行填充:In [59]: df1.fillna(value=5) Out[59]: A B C D F E 2013-01-01 0.000000 0.000000 -1.509059 5 5.0 1.0 2013-01-02 1.212112 -0.173215 0.119209 5 1.0 1.0 2013-01-03 -0.861849 -2.104569 -0.494929 5 2.0 5.0 2013-01-04 0.721555 -0.706771 -1.039575 5 3.0 5.04、 对数据进行布尔填充:n [60]: pd.isnull(df1) Out[60]: A B C D F E 2013-01-01 False False False False True False 2013-01-02 False False False False False False 2013-01-03 False False False False False True 2013-01-04 False False False False False True五、 相关操作详情请参与 基本的二进制操作统计(相关操作通常情况下不包括缺失值)1、 执行描述性统计:In [61]: df.mean() Out[61]: A -0.004474 B -0.383981 C -0.687758 D 5.000000 F 3.000000 dtype: float642、 在其他轴上进行相同的操作:In [62]: df.mean(1) Out[62]: 2013-01-01 0.872735 2013-01-02 1.431621 2013-01-03 0.707731 2013-01-04 1.395042 2013-01-05 1.883656 2013-01-06 1.592306 Freq: D, dtype: float643、 对于拥有不同维度,需要对齐的对象进行操作。Pandas 会自动的沿着指定的维度进行广播:In [63]: s = pd.Series([1,3,5,np.nan,6,8], index=dates).shift(2) In [64]: s Out[64]: 2013-01-01 NaN 2013-01-02 NaN 2013-01-03 1.0 2013-01-04 3.0 2013-01-05 5.0 2013-01-06 NaN Freq: D, dtype: float64 In [65]: df.sub(s, axis='index') Out[65]: A B C D F 2013-01-01 NaN NaN NaN NaN NaN 2013-01-02 NaN NaN NaN NaN NaN 2013-01-03 -1.861849 -3.104569 -1.494929 4.0 1.0 2013-01-04 -2.278445 -3.706771 -4.039575 2.0 0.0 2013-01-05 -5.424972 -4.432980 -4.723768 0.0 -1.0 2013-01-06 NaN NaN NaN NaN NaNApply1、 对数据应用函数:In [66]: df.apply(np.cumsum) Out[66]: A B C D F 2013-01-01 0.000000 0.000000 -1.509059 5 NaN 2013-01-02 1.212112 -0.173215 -1.389850 10 1.0 2013-01-03 0.350263 -2.277784 -1.884779 15 3.0 2013-01-04 1.071818 -2.984555 -2.924354 20 6.0 2013-01-05 0.646846 -2.417535 -2.648122 25 10.0 2013-01-06 -0.026844 -2.303886 -4.126549 30 15.0 In [67]: df.apply(lambda x: x.max() - x.min()) Out[67]: A 2.073961 B 2.671590 C 1.785291 D 0.000000 F 4.000000 dtype: float64直方图具体请参照:直方图和离散化。In [68]: s = pd.Series(np.random.randint(0, 7, size=10)) In [69]: s Out[69]: 0 4 1 2 2 1 3 2 4 6 5 4 6 4 7 6 8 4 9 4 dtype: int64 In [70]: s.value_counts() Out[70]: 4 5 6 2 2 2 1 1 dtype: int64字符串方法Series对象在其str属性中配备了一组字符串处理方法,可以很容易的应用到数组中的每个元素,如下段代码所示。更多详情请参考:字符串向量化方法。In [71]: s = pd.Series(['A', 'B', 'C', 'Aaba', 'Baca', np.nan, 'CABA', 'dog', 'cat']) In [72]: s.str.lower() Out[72]: 0 a 1 b 2 c 3 aaba 4 baca 5 NaN 6 caba 7 dog 8 cat dtype: object六、 合并Pandas 提供了大量的方法能够轻松的对Series,DataFrame和Panel对象进行各种符合各种逻辑关系的合并操作。具体请参阅:合并。ConcatIn [73]: df = pd.DataFrame(np.random.randn(10, 4)) In [74]: df Out[74]: 0 1 2 3 0 -0.548702 1.467327 -1.015962 -0.483075 1 1.637550 -1.217659 -0.291519 -1.745505 2 -0.263952 0.991460 -0.919069 0.266046 3 -0.709661 1.669052 1.037882 -1.705775 4 -0.919854 -0.042379 1.247642 -0.009920 5 0.290213 0.495767 0.362949 1.548106 6 -1.131345 -0.089329 0.337863 -0.945867 7 -0.932132 1.956030 0.017587 -0.016692 8 -0.575247 0.254161 -1.143704 0.215897 9 1.193555 -0.077118 -0.408530 -0.862495 # break it into pieces In [75]: pieces = [df[:3], df[3:7], df[7:]] In [76]: pd.concat(pieces) Out[76]: 0 1 2 3 0 -0.548702 1.467327 -1.015962 -0.483075 1 1.637550 -1.217659 -0.291519 -1.745505 2 -0.263952 0.991460 -0.919069 0.266046 3 -0.709661 1.669052 1.037882 -1.705775 4 -0.919854 -0.042379 1.247642 -0.009920 5 0.290213 0.495767 0.362949 1.548106 6 -1.131345 -0.089329 0.337863 -0.945867 7 -0.932132 1.956030 0.017587 -0.016692 8 -0.575247 0.254161 -1.143704 0.215897 9 1.193555 -0.077118 -0.408530 -0.862495Join类似于 SQL 类型的合并,具体请参阅:数据库风格的连接In [77]: left = pd.DataFrame({'key': ['foo', 'foo'], 'lval': [1, 2]}) In [78]: right = pd.DataFrame({'key': ['foo', 'foo'], 'rval': [4, 5]}) In [79]: left Out[79]: key lval 0 foo 1 1 foo 2 In [80]: right Out[80]: key rval 0 foo 4 1 foo 5 In [81]: pd.merge(left, right, on='key') Out[81]: key lval rval 0 foo 1 4 1 foo 1 5 2 foo 2 4 3 foo 2 5另一个例子:In [82]: left = pd.DataFrame({'key': ['foo', 'bar'], 'lval': [1, 2]}) In [83]: right = pd.DataFrame({'key': ['foo', 'bar'], 'rval': [4, 5]}) In [84]: left Out[84]: key lval 0 foo 1 1 bar 2 In [85]: right Out[85]: key rval 0 foo 4 1 bar 5 In [86]: pd.merge(left, right, on='key') Out[86]: key lval rval 0 foo 1 4 1 bar 2 5Append将一行连接到一个DataFrame上,具体请参阅附加:In [87]: df = pd.DataFrame(np.random.randn(8, 4), columns=['A','B','C','D']) In [88]: df Out[88]: A B C D 0 1.346061 1.511763 1.627081 -0.990582 1 -0.441652 1.211526 0.268520 0.024580 2 -1.577585 0.396823 -0.105381 -0.532532 3 1.453749 1.208843 -0.080952 -0.264610 4 -0.727965 -0.589346 0.339969 -0.693205 5 -0.339355 0.593616 0.884345 1.591431 6 0.141809 0.220390 0.435589 0.192451 7 -0.096701 0.803351 1.715071 -0.708758 In [89]: s = df.iloc[3] In [90]: df.append(s, ignore_index=True) Out[90]: A B C D 0 1.346061 1.511763 1.627081 -0.990582 1 -0.441652 1.211526 0.268520 0.024580 2 -1.577585 0.396823 -0.105381 -0.532532 3 1.453749 1.208843 -0.080952 -0.264610 4 -0.727965 -0.589346 0.339969 -0.693205 5 -0.339355 0.593616 0.884345 1.591431 6 0.141809 0.220390 0.435589 0.192451 7 -0.096701 0.803351 1.715071 -0.708758 8 1.453749 1.208843 -0.080952 -0.264610七、 分组对于”group by”操作,我们通常是指以下一个或多个操作步骤:(Splitting)按照一些规则将数据分为不同的组;(Applying)对于每组数据分别执行一个函数;(Combining)将结果组合到一个数据结构中;详情请参阅:Grouping sectionIn [91]: df = pd.DataFrame({'A' : ['foo', 'bar', 'foo', 'bar', ....: 'foo', 'bar', 'foo', 'foo'], ....: 'B' : ['one', 'one', 'two', 'three', ....: 'two', 'two', 'one', 'three'], ....: 'C' : np.random.randn(8), ....: 'D' : np.random.randn(8)}) ....: In [92]: df Out[92]: A B C D 0 foo one -1.202872 -0.055224 1 bar one -1.814470 2.395985 2 foo two 1.018601 1.552825 3 bar three -0.595447 0.166599 4 foo two 1.395433 0.047609 5 bar two -0.392670 -0.136473 6 foo one 0.007207 -0.561757 7 foo three 1.928123 -1.6230331、 分组并对每个分组执行sum函数:In [93]: df.groupby('A').sum() Out[93]: C D A bar -2.802588 2.42611 foo 3.146492 -0.639582、 通过多个列进行分组形成一个层次索引,然后执行函数:In [94]: df.groupby(['A','B']).sum() Out[94]: C D A B bar one -1.814470 2.395985 three -0.595447 0.166599 two -0.392670 -0.136473 foo one -1.195665 -0.616981 three 1.928123 -1.623033 two 2.414034 1.600434八、 改变形状详情请参阅 层次索引 和 改变形状。StackIn [95]: tuples = list(zip(*[['bar', 'bar', 'baz', 'baz', ....: 'foo', 'foo', 'qux', 'qux'], ....: ['one', 'two', 'one', 'two', ....: 'one', 'two', 'one', 'two']])) ....: In [96]: index = pd.MultiIndex.from_tuples(tuples, names=['first', 'second']) In [97]: df = pd.DataFrame(np.random.randn(8, 2), index=index, columns=['A', 'B']) In [98]: df2 = df[:4] In [99]: df2 Out[99]: A B first second bar one 0.029399 -0.542108 two 0.282696 -0.087302 baz one -1.575170 1.771208 two 0.816482 1.100230In [100]: stacked = df2.stack() In [101]: stacked Out[101]: first second bar one A 0.029399 B -0.542108 two A 0.282696 B -0.087302 baz one A -1.575170 B 1.771208 two A 0.816482 B 1.100230 dtype: float64In [102]: stacked.unstack() Out[102]: A B first second bar one 0.029399 -0.542108 two 0.282696 -0.087302 baz one -1.575170 1.771208 two 0.816482 1.100230 In [103]: stacked.unstack(1) Out[103]: second one two first bar A 0.029399 0.282696 B -0.542108 -0.087302 baz A -1.575170 0.816482 B 1.771208 1.100230 In [104]: stacked.unstack(0) Out[104]: first bar baz second one A 0.029399 -1.575170 B -0.542108 1.771208 two A 0.282696 0.816482 B -0.087302 1.100230数据透视表详情请参阅:数据透视表.In [105]: df = pd.DataFrame({'A' : ['one', 'one', 'two', 'three'] * 3, .....: 'B' : ['A', 'B', 'C'] * 4, .....: 'C' : ['foo', 'foo', 'foo', 'bar', 'bar', 'bar'] * 2, .....: 'D' : np.random.randn(12), .....: 'E' : np.random.randn(12)}) .....: In [106]: df Out[106]: A B C D E 0 one A foo 1.418757 -0.179666 1 one B foo -1.879024 1.291836 2 two C foo 0.536826 -0.009614 3 three A bar 1.006160 0.392149 4 one B bar -0.029716 0.264599 5 one C bar -1.146178 -0.057409 6 two A foo 0.100900 -1.425638 7 three B foo -1.035018 1.024098 8 one C foo 0.314665 -0.106062 9 one A bar -0.773723 1.824375 10 two B bar -1.170653 0.595974 11 three C bar 0.648740 1.167115可以从这个数据中轻松的生成数据透视表:In [107]: pd.pivot_table(df, values='D', index=['A', 'B'], columns=['C']) Out[107]: C bar foo A B one A -0.773723 1.418757 B -0.029716 -1.879024 C -1.146178 0.314665 three A 1.006160 NaN B NaN -1.035018 C 0.648740 NaN two A NaN 0.100900 B -1.170653 NaN C NaN 0.536826九、 时间序列Pandas 在对频率转换进行重新采样时拥有简单、强大且高效的功能(如将按秒采样的数据转换为按5分钟为单位进行采样的数据)。这种操作在金融领域非常常见。具体参考:时间序列。In [108]: rng = pd.date_range('1/1/2012', periods=100, freq='S') In [109]: ts = pd.Series(np.random.randint(0, 500, len(rng)), index=rng) In [110]: ts.resample('5Min').sum() Out[110]: 2012-01-01 25083 Freq: 5T, dtype: int641、 时区表示:In [111]: rng = pd.date_range('3/6/2012 00:00', periods=5, freq='D') In [112]: ts = pd.Series(np.random.randn(len(rng)), rng) In [113]: ts Out[113]: 2012-03-06 0.464000 2012-03-07 0.227371 2012-03-08 -0.496922 2012-03-09 0.306389 2012-03-10 -2.290613 Freq: D, dtype: float64 In [114]: ts_utc = ts.tz_localize('UTC') In [115]: ts_utc Out[115]: 2012-03-06 00:00:00+00:00 0.464000 2012-03-07 00:00:00+00:00 0.227371 2012-03-08 00:00:00+00:00 -0.496922 2012-03-09 00:00:00+00:00 0.306389 2012-03-10 00:00:00+00:00 -2.290613 Freq: D, dtype: float642、 时区转换:In [116]: ts_utc.tz_convert('US/Eastern') Out[116]: 2012-03-05 19:00:00-05:00 0.464000 2012-03-06 19:00:00-05:00 0.227371 2012-03-07 19:00:00-05:00 -0.496922 2012-03-08 19:00:00-05:00 0.306389 2012-03-09 19:00:00-05:00 -2.290613 Freq: D, dtype: float643、 时间跨度转换:In [117]: rng = pd.date_range('1/1/2012', periods=5, freq='M') In [118]: ts = pd.Series(np.random.randn(len(rng)), index=rng) In [119]: ts Out[119]: 2012-01-31 -1.134623 2012-02-29 -1.561819 2012-03-31 -0.260838 2012-04-30 0.281957 2012-05-31 1.523962 Freq: M, dtype: float64 In [120]: ps = ts.to_period() In [121]: ps Out[121]: 2012-01 -1.134623 2012-02 -1.561819 2012-03 -0.260838 2012-04 0.281957 2012-05 1.523962 Freq: M, dtype: float64 In [122]: ps.to_timestamp() Out[122]: 2012-01-01 -1.134623 2012-02-01 -1.561819 2012-03-01 -0.260838 2012-04-01 0.281957 2012-05-01 1.523962 Freq: MS, dtype: float644、 时期和时间戳之间的转换使得可以使用一些方便的算术函数。In [123]: prng = pd.period_range('1990Q1', '2000Q4', freq='Q-NOV') In [124]: ts = pd.Series(np.random.randn(len(prng)), prng) In [125]: ts.index = (prng.asfreq('M', 'e') + 1).asfreq('H', 's') + 9 In [126]: ts.head() Out[126]: 1990-03-01 09:00 -0.902937 1990-06-01 09:00 0.068159 1990-09-01 09:00 -0.057873 1990-12-01 09:00 -0.368204 1991-03-01 09:00 -1.144073 Freq: H, dtype: float64十、 Categorical从 0.15 版本开始,pandas 可以在DataFrame中支持 Categorical 类型的数据,详细 介绍参看:Categorical 简介和API documentation。In [127]: df = pd.DataFrame({"id":[1,2,3,4,5,6], "raw_grade":['a', 'b', 'b', 'a', 'a', 'e']})1、 将原始的grade转换为 Categorical 数据类型:In [128]: df["grade"] = df["raw_grade"].astype("category") In [129]: df["grade"] Out[129]: 0 a 1 b 2 b 3 a 4 a 5 e Name: grade, dtype: category Categories (3, object): [a, b, e]2、 将 Categorical 类型数据重命名为更有意义的名称:In [130]: df["grade"].cat.categories = ["very good", "good", "very bad"]3、 对类别进行重新排序,增加缺失的类别:In [131]: df["grade"] = df["grade"].cat.set_categories(["very bad", "bad", "medium", "good", "very good"]) In [132]: df["grade"] Out[132]: 0 very good 1 good 2 good 3 very good 4 very good 5 very bad Name: grade, dtype: category Categories (5, object): [very bad, bad, medium, good, very good]4、 排序是按照 Categorical 的顺序进行的而不是按照字典顺序进行:In [133]: df.sort_values(by="grade") Out[133]: id raw_grade grade 5 6 e very bad 1 2 b good 2 3 b good 0 1 a very good 3 4 a very good 4 5 a very good5、 对 Categorical 列进行排序时存在空的类别:In [134]: df.groupby("grade").size() Out[134]: grade very bad 1 bad 0 medium 0 good 2 very good 3 dtype: int64十一、 画图具体文档参看:绘图文档。In [135]: ts = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2000', periods=1000)) In [136]: ts = ts.cumsum() In [137]: ts.plot() Out[137]: <matplotlib.axes._subplots.AxesSubplot at 0x7ff2ab2af550>对于DataFrame来说,plot是一种将所有列及其标签进行绘制的简便方法:In [138]: df = pd.DataFrame(np.random.randn(1000, 4), index=ts.index, .....: columns=['A', 'B', 'C', 'D']) .....: In [139]: df = df.cumsum() In [140]: plt.figure(); df.plot(); plt.legend(loc='best') Out[140]: <matplotlib.legend.Legend at 0x7ff29c8163d0>十二、 导入和保存数据CSV参考:写入 CSV 文件。1、 写入 csv 文件:In [141]: df.to_csv('foo.csv')2、 从 csv 文件中读取:In [142]: pd.read_csv('foo.csv') Out[142]: Unnamed: 0 A B C D 0 2000-01-01 0.266457 -0.399641 -0.219582 1.186860 1 2000-01-02 -1.170732 -0.345873 1.653061 -0.282953 2 2000-01-03 -1.734933 0.530468 2.060811 -0.515536 3 2000-01-04 -1.555121 1.452620 0.239859 -1.156896 4 2000-01-05 0.578117 0.511371 0.103552 -2.428202 5 2000-01-06 0.478344 0.449933 -0.741620 -1.962409 6 2000-01-07 1.235339 -0.091757 -1.543861 -1.084753 .. ... ... ... ... ... 993 2002-09-20 -10.628548 -9.153563 -7.883146 28.313940 994 2002-09-21 -10.390377 -8.727491 -6.399645 30.914107 995 2002-09-22 -8.985362 -8.485624 -4.669462 31.367740 996 2002-09-23 -9.558560 -8.781216 -4.499815 30.518439 997 2002-09-24 -9.902058 -9.340490 -4.386639 30.105593 998 2002-09-25 -10.216020 -9.480682 -3.933802 29.758560 999 2002-09-26 -11.856774 -10.671012 -3.216025 29.369368 [1000 rows x 5 columns]HDF5参考:HDF5 存储1、 写入 HDF5 存储:In [143]: df.to_hdf('foo.h5','df')2、 从 HDF5 存储中读取:In [144]: pd.read_hdf('foo.h5','df') Out[144]: A B C D 2000-01-01 0.266457 -0.399641 -0.219582 1.186860 2000-01-02 -1.170732 -0.345873 1.653061 -0.282953 2000-01-03 -1.734933 0.530468 2.060811 -0.515536 2000-01-04 -1.555121 1.452620 0.239859 -1.156896 2000-01-05 0.578117 0.511371 0.103552 -2.428202 2000-01-06 0.478344 0.449933 -0.741620 -1.962409 2000-01-07 1.235339 -0.091757 -1.543861 -1.084753 ... ... ... ... ... 2002-09-20 -10.628548 -9.153563 -7.883146 28.313940 2002-09-21 -10.390377 -8.727491 -6.399645 30.914107 2002-09-22 -8.985362 -8.485624 -4.669462 31.367740 2002-09-23 -9.558560 -8.781216 -4.499815 30.518439 2002-09-24 -9.902058 -9.340490 -4.386639 30.105593 2002-09-25 -10.216020 -9.480682 -3.933802 29.758560 2002-09-26 -11.856774 -10.671012 -3.216025 29.369368 [1000 rows x 4 columns]Excel参考:MS Excel1、 写入excel文件:In [145]: df.to_excel('foo.xlsx', sheet_name='Sheet1')2、 从excel文件中读取:In [146]: pd.read_excel('foo.xlsx', 'Sheet1', index_col=None, na_values=['NA']) Out[146]: A B C D 2000-01-01 0.266457 -0.399641 -0.219582 1.186860 2000-01-02 -1.170732 -0.345873 1.653061 -0.282953 2000-01-03 -1.734933 0.530468 2.060811 -0.515536 2000-01-04 -1.555121 1.452620 0.239859 -1.156896 2000-01-05 0.578117 0.511371 0.103552 -2.428202 2000-01-06 0.478344 0.449933 -0.741620 -1.962409 2000-01-07 1.235339 -0.091757 -1.543861 -1.084753 ... ... ... ... ... 2002-09-20 -10.628548 -9.153563 -7.883146 28.313940 2002-09-21 -10.390377 -8.727491 -6.399645 30.914107 2002-09-22 -8.985362 -8.485624 -4.669462 31.367740 2002-09-23 -9.558560 -8.781216 -4.499815 30.518439 2002-09-24 -9.902058 -9.340490 -4.386639 30.105593 2002-09-25 -10.216020 -9.480682 -3.933802 29.758560 2002-09-26 -11.856774 -10.671012 -3.216025 29.369368 [1000 rows x 4 columns]十三、陷阱如果你尝试某个操作并且看到如下异常:>>> if pd.Series([False, True, False]): print("I was true") Traceback ... ValueError: The truth value of an array is ambiguous. Use a.empty, a.any() or a.all().解释及处理方式请见比较。同时请见陷阱。 -
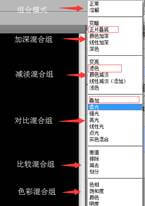
PS功能精通课 第一课 我用双手成就你的梦想课程结构精通14节+提升22节+实战36节交作业M站:m.dapengjiaoyu.com上传图片格式:JPG单张作业不可大过2M、最多上传9张、9张不可大过9M认识软件美国Adobe公司开发 中文:奥多比PS:位图的处理软件位图:图片缩小拉大之后图像会失真、色彩表现力好,文件大PS的使用方向:摄影后期、效果图的后期处理、图像合成、电影海报、电商、网页设计、UI设计、等等...很多方面,较为广泛Ai:矢量图的处理软件矢量图:图片缩小拉大之后图像不会失真、色彩表现不如ps细腻、层次感不强、文件小Ai的使用方向:印刷(名片)、包装盒的设计制作、企业VI手册设计(企业形象识别系统)、LOGO设计等ID:专业书籍排版软件ID的使用方向:杂志、广告设计、目录、零售商设计工作室和报纸出版方案等PS基本操作{card-default label="操作步骤" width=""}1.新建画布(快捷键Ctrl+N)①分辨率:打印时用300分辨率(大尺寸设计稿分比率会根据具体情况变小);屏幕显示时用72分辨率②颜色模式:显示时用RGB RGB代表红绿蓝 打印时用CMYK CMYK代表青、品红、黄、黑2.打开(在工作区域外)①文件——打开(快捷键Ctrl+O)②拖拽打开:在计算机里选中需要打开的文件点击并拖拽至ps图标上,然后移动到菜单栏或属性栏3.置入(在工作区域内):拖拽到画布中,需确定置入命令,可直接按回车Enter确定4.保存(快捷键Ctrl+S):格式psd留给设计师自己的源文件可再次修改, Jpg图片格式 不可修改, png透底图 背景透明5.另存为:快捷键Ctrl+Shift+S6.存储为web所用格式:快捷键Ctrl+Shift+Alt+S(可以更改素材质量大小,优化文件大小)7.调整ps:编辑—首选项—暂存盘 快捷键Ctrl+K勾选所有硬盘可缓解卡顿{/card-default}快捷键整理新建画布:Ctrl+N打开:Ctrl+O保存:Ctrl+S另存为:Ctrl+Shift+S存储为web所用格式:Ctrl+Shift+Alt+S 第二课 揭开ps的神秘面纱画布操作{card-default label="操作步骤" width=""}1.放大缩小画布:Alt+鼠标滚轮 或 Ctrl+加减键 或缩放工具(Alt缩小)2.百分之百显示:Ctrl+1 根据显示器显示:Ctrl+0(零)3.移动画板:按住空格键可临时切换为抓手工具鼠标左键拖拽即可4.撤销一步:Ctrl+Z 撤销多步:Ctrl+Alt+Z 还原多步:Ctrl+Shift+Z5.自由变换:Ctrl+T①普通变换:通过对角点拉伸,鼠标放在对角(出现弯箭头)旋转。按Alt(中心点)和Shift(等比)以中心点等比例缩放{/card-default}图层基本操作{card-default label="操作步骤" width=""}1.解锁背景图层:点击图层后方锁头解锁2.显示隐藏图层:点击该图层前的眼睛图标3.删除图层:选中图层按delete键删除 或选中图层后点击下方垃圾桶图标 或选中图层拖拽至垃圾桶图标上4.创建新图层:点击垃圾桶左侧的图标(快捷键Ctrl+Alt+Shift+N)5.上色(前景色与背景色,需要自行添加新图层)6.恢复默认前景色和背景色(黑白):按D7.切换前景色与背景色:点击弯箭头或按X填充前景色:Alt+Delete填充背景色:Ctrl+Delete{/card-default}移动工具(快捷键V){card-default label="操作步骤" width=""}移动工具可以移动,可以复制,还可以跨画布复制对齐:必须有两个及以上图层分布:必须有三个及以上图层快速选择图层:移动工具下按住ctrl可以临时切换到自动选择模式,同时按住Shift可以进行加选或减选{/card-default}画笔(快捷键B){card-default label="操作步骤" width=""}1.画笔加号情况:可能开了大写或画笔过大2.画笔工具用于涂抹前景色3.画笔大小更改:P后面【】 画笔硬度更改:Shift+P后面【】{/card-default}快捷键整理适应显示器显示:Ctrl+0百分百显示:Ctrl+1撤销:Ctrl+Z自由变换:Ctrl+T还原多步:Ctrl+Shift+Z撤销多步:Ctrl+Alt+Z画笔(快捷键:B)新建图层:Ctrl+Alt+Shift+N填充前景色:Alt+Delete填充背景色:Ctrl+Delete第三课 成为大神前的第一步图层操作{card-default label="操作步骤" width=""}1.复制图层①移动工具下,按住Alt点击并拖拽可以复制,按住Shift可以控制复制的图层水平或垂直方向平移②原位复制,快捷键Ctrl+J2.编组:Ctrl+G 取消编组:Ctrl+Shift+G3.合并图层:Ctrl+E(尽量少用)4.分离图像:Ctrl+Shift+J把选中的内容剪切出来并放在原位{/card-default}选框工具(快捷键M,切换工具Shift+M){card-default label="操作步骤" width=""}1.选框:流动的虚线(蚂蚁线)2.绘制方法:点击并拖拽(点击鼠标不要松开)按住Shift绘制正图形选区,按住Alt以鼠标为中心绘制选区,按Shift+Alt以鼠标为中心绘制正图形选区3.取消选区:Ctrl+D4.羽化:制作边缘虚化的效果属性栏处进行羽化时选择羽化后填充(选框绘画之前)羽化需要选择—修改—羽化快捷键Shift+F6进行羽化(选框画完之后)5.载入选区:按住Ctrl点击该图层的图层缩览图{/card-default}选区的操作{card-default label="操作步骤" width=""}1.新选区:新绘制的选区每次都形成一个新选区2.添加到选区:新绘制的选区与之前绘制的选区进行相加(快捷方法先按住Shift再绘制新选区)3.从选区减去:新绘制的选区与之前绘制的选区进行相减(快捷方法先按住Alt再绘制新选区)4.与选区交叉:新绘制的选区与之前绘制的选区相交部分留下(快捷方法先按住Shift+Alt再绘制新选区)5.绘制时移动:绘制时按住空格键可以移动选区{/card-default}快捷键整理编组:Ctrl+G(原位)复制:Ctrl+J合并图层:Ctrl+E取消编组:Ctrl+Shift+G填充背景色:Ctrl+Delete填充前景色:Alt+Delete取消选区:Ctrl+D分离图像:Ctrl+Shift+J 羽化:Shift+F6第四课 神奇的布尔运算矢量工具(快捷键U,切换工具Shift+U){card-default label="操作步骤" width=""}1.形状模式:在绘制过程中会自动新建图层,默认自动填充前景色2.颜色填充:纯色填充、渐变填充、图案填充3.图形描边:纯色填充、渐变填充、图案填充;描边大小;描边选项4.图形大小:属性栏处可以精确调整大小或Ctrl+T5.图形绘制:按住Shift可以绘制正图形,按住Alt键可以以鼠标为中心点绘制图形,按住Shift+Alt可以以鼠标为中心点绘制正图形6.圆角矩形:绘制的时候先设置半径,高版本可以在属性栏中修改(CS版本的就不好意思啦,不能在属性栏调整,因为没有这个功能,哈哈哈!!!)7.多边形:绘制的时候先设置多边形的边数与平滑星星等8.直线:绘制的时候先改变线的粗细,按住shift可以成角度约束9.自定形状:软件预设好的形状,方便使用,还可以追加。10.自定形状追加:设置—全部—追加11.定义自定形状:选择想要定义的图层右击选择定义自定形状(必须有路径的图层)12.布尔运算(通过形状层的加、减、交得到新的图形):同选区操作13.矢量图形计算后:必须要合并形状组件{/card-default}小黑小白{card-default label="操作步骤" width=""}1.小黑(A):移动和复制路径,单独选中图形2.小白(A):选择和移动路径的上锚点,以及调节控制手柄,按住Shift可以加选锚点{/card-default}渐变工具在属性栏处选择一种渐变类型,并设置渐变颜色和其他属性等,创建渐变快捷键整理填充前景色:Alt+Delete填充背景色:Ctrl+Delete分离图像:Ctrl+Shift+J取消选区:Ctrl+D 第五课 祖传抠图技法套索工具{card-default label="操作步骤" width=""}1.套索工具:大致框选,不适合精确抠图2.多边形套索工具:适合抠有棱角的图片,直线(回车可快速成选区)3.磁性套索工具:具有磁性,可以识别物体边缘(边缘清晰),操作发生偏移可以通过Delete进行点的删除(回车可快速成选区)a 宽度:该值决定了以光标中心为基准,其周围有多少个像素能够被工具检测到。边界清晰时数值高b 对比度:设置工具感应图像边缘的灵敏度,图像清晰时数值高c 频率:决定产生的锚点数量。数值越高,捕捉的边界越准确{/card-default}快速选择工具(属于画笔类){card-default label="操作步骤" width=""}1.调成大小:P后面的【】可以调节画笔大小2.可以移动十字光标,快速连续选择相近的图像,会自动识别边缘(创建选框)3.选区的反向选择:Ctrl+Shift+I{/card-default}魔棒工具{card-default label="操作步骤" width=""}1.可以创建选区,选择颜色相近的范围2.容差值越大,选择颜色相似的范围越大,5~35之间3.不勾选连续时,主体物与背景颜色相近时,主体物也会选中4.魔棒工具抠图适用情况:背景是纯色,或背景与主体物颜色差距大{/card-default}色彩范围{card-default label="操作步骤" width=""}1.选择—色彩范围 选择改为取样颜色 图形下面选择选择范围2.根据图像的颜色范围,进行创建选区白色为被选中的,黑色没被选中的,灰色透明的{/card-default}橡皮擦工具{card-default label="操作步骤" width=""}1.橡皮擦工具:直接擦涂,删掉不需要的图像2.魔术橡皮擦:直接删掉颜色相近的区域,容差值与魔棒相同{/card-default}其他辅助操作{card-default label="操作步骤" width=""}1.图层顺序:下/上移一层图层 Ctrl+【】 置底/置顶图层 Ctrl+Shift+【】2.收缩(选择—修改):在原有基础上进行缩小选区{/card-default}快捷键整理反向选则:Ctrl+Shift+I 下/上移动图层:Ctrl+【】置底/置顶:Ctrl+Shift+【】第六课 高效修图法污点修复画笔{card-default label="操作步骤" width=""}1.调节大小:P后面的【】进行调节2.类型:内容识别(常用)/创建纹理/近似匹配3.内容识别:点击需要修复的区域。软件会自动在他的周围进行取样,通过计算对其进行光线和明暗的匹配,并进行羽化融合4.创建纹理:可以创建纹理,纹理为ps自带不可修改5.近似匹配:使用工具边缘的像素来修补图像 扩散数值为画笔附近几像素的范围。(可以自动调节明暗){/card-default}修复画笔工具{card-default label="操作步骤" width=""}1.调节大小:P后面的【】进行调节2.取样:在需要修复的区域四周,找到颜色相似的区域,按住Alt键,鼠标点击进行取样,然后在需要修复的区域点击或涂抹,(在修复时,修复画笔尽量要比修复的区域大,否则,修复效果不是很好。)3.对齐:勾选对齐后吸取点跟随修复点移动,不勾选每次单击修复都是用同一吸取点去修复4.图案:直接涂抹即可,不需要取样,类似图案叠加{/card-default}修补工具{card-default label="操作步骤" width=""}1.源:选区位置被鼠标停留位置覆盖2.目标:选区位置覆盖鼠标停留位置{/card-default}内容感知移动工具可以移动画面当中物体的位置,移动 之后可以自动填充。可以在需要修改的位置绘制选区,移动选区到画布外,留一小部分选区再画布当中,来用于修补水印红眼工具可以修复相机在光线昏暗的情况下,产生的红眼效果,点击红眼部位,会自动修复。(了解即可)仿制图章{card-default label="操作步骤" width=""}1.使用方法同修复画笔一致2.仿制图章工具与修复画笔工具的区别:①仿制图章是无损仿制,取样什么颜色/皮肤,仿制的就是什么样子②修复画笔有一个运算过程,在涂抹当中将取样图像和目标位置融合,自动适应周围环境{/card-default}图案图章工具选择图案可以涂背景,类似图案添加液化{card-default label="操作步骤" width=""}(快捷键:Ctrl+Shift+X)如果液化点不开或者灰色的,首选项-性能-使用图形处理器勾选上1.位置:滤镜—液化2.向前变形:可以制作瘦身瘦脸效果3.重建工具:可以恢复之前的变形4.顺时针旋转扭曲工具:按住alt键点击可以逆时针旋转5.褶皱工具(挤压、褶皱效果)6.膨胀工具(与褶皱工具相反)7.左推工具(从上往下是往左推,从下往上是往右推)8.冻结蒙版工具(保护图层)9.解冻蒙版工具(取消冻结的蒙版)10.人脸识别11.移动工具、放大缩小{/card-default}内容识别(快捷键:Shift+F5)通过绘制选区选择 需要修复的区域,软件会自动识别与画面不匹配的区域,进行修复图像快捷键整理液化 Ctrl+Shift+X内容识别 Shift+F5 第七课 玩转钢笔钢笔工具(快捷键P){card-default label="操作步骤" width=""}1.钢笔工具:①绘制直线的方法:在起始点位置点击定点,连续点击,按住Shift键,可以绘制成角度的直线②绘制曲线的方法:在起始点位置点击定点,在下一点处点击并拖拽鼠标,拉出弧线,会出现控制手柄,再一次绘制时,需要按住Alt键取消一侧手柄③自动添加删除:可以直接在路径上点击添加锚点或者点击锚点删除锚点④临时切换:按住Ctrl键可以临时切换到小白工具进行锚点移动(自带控制手柄,可以调节弧度大小)⑤将路径转换为选区:右击,选择建立选区、或Ctrl+Enter回车、或在路径面板下,Ctrl+路径缩览图⑥Delete键删除最后一个锚点的同时会结束钢笔工具这一次路径的绘制2.自由钢笔工具:点击拖拽鼠标可以画出流畅的线条路径。右击路径,选择画笔勾选模拟压力(需先设置好画笔大小、硬度等)3.转换点工具:点击曲线位置的点,可以将其变成直线。点击直线位置的点,选中并拖拽,可以出现控制手柄,调节弧度{/card-default}路径面板{card-default label="操作步骤" width=""}1.路径面板可以实现选区与路径的互相转换2.储存为jpg,psd时,路径面板可以储存路径,类似图层,便于抠图便于工作{/card-default}画笔(快捷键:B){card-default label="操作步骤" width=""}1.载入画笔:设置中找到载入画笔,找到画笔点击载入,右键可以删除画笔2.画笔面板(快捷键F5):形状动态、散布、颜色动态3.定义画笔预设:编辑—定义画笔预设 画笔只认黑白灰,黑(实色颜色)、白(没有颜色)、灰(半透明){/card-default}第八课 多元化的文字文字工具{card-default label="操作步骤" width=""}(推荐:www.qiuziti.com来找字体)1.横排文字蒙版(直排文字蒙版)工具:点击就会出现红色蒙版,输入文字确定后不会新建图层,并且文字会变为选区2.横排文字(竖排文字)工具:点击会自动新建文字图层,可以再属性栏处更改文字属性3.确定文字输入:属性栏的对勾 或Ctrl+Enter回车 或小键盘下的Enter4.全选:Ctrl+A或双击文字图层缩览图5.调节字间距:Alt+左右箭头6.调节行间距:Alt+上下箭头7.点文字:不会自动换行,换行需要手动回车进行换行,适合做标题文字8.段文字(区域文字):在画布上点击并拖拽拉出文本框,会自动换行,文字溢出时下方有加号提示,适合做说明文字9.路径文字:用钢笔或者形状工具,绘制一段路径,将文字工具的光标放在路径上,点击输入文字。用小白调节文字形态{/card-default}第九课 图层样式+图层混合模式混合模式(27个){card-default label="操作步骤" width=""}1.使用要求:必须两个或两个以上的图层才能进行混合2.混合模式分组:A.组合模式:需要降低图层的不透明度才能产生作用B.加深混合组:可以使图像变暗,将下方图层中的亮色被上方较暗的像素替代C.减淡混合组:与加深混合组相反,可以使图像变亮,将下方图层中的暗色被上方较亮的像素替代D.对比混合组:50%的灰色完全消失,高于50%灰的像素会使底图变亮,低于50%灰的像素会使底图变暗E.比较混合组:相同的区域显示为黑色,不同的区域显示为灰度层次或彩色。当图层中包含白色,白色区域会使底层图像反相,而黑色不会对底层图像产生影响。F.色彩混合组:将色彩的色相、饱和度和亮度,替换给下方图层3.重要的混合模式选项(4个)①加深混合组:正片叠底(去白留黑)②减淡混合组:滤色(去黑留白)③比较混合组:叠加,使你的颜色跟下方图层进行有机的的叠加,同时修改下方图层的本身的亮度和明暗程度,比较柔和的效果④柔光 ,效果更好,画面更融合{/card-default}图层样式{card-default label="操作步骤" width=""}1.添加图层样式:①双击图层缩览图的后方,弹出对话框②点击图层面板下方Fx按钮,添加图层样式③图层菜单中选择④在画布区域右击弹出混合选项 选择(移动工具、抓手工具、放大镜工具不可)2.复制图层样式:按住Alt键点击图层样式Fx进行拖拽到需要复制的图层或在图层上右击鼠标选择拷贝图层样式 在需要复制的图层上右击选择粘贴图层样式3.填充:可以将颜色降低透明度,图层样式不变{/card-default}第十课 蒙版带你领略台前幕后的故事快速蒙版(快捷键Q)快速蒙版是一种选区工具 结合画笔工具使用,常用与影楼。双击快速蒙版,可以更改快速蒙版建立的选区形式剪贴蒙版(上图下形){card-default label="操作步骤" width=""}1.原理是将上层图层置于下层图层内,他们必须是上下层关系2.下方图层可以是形状、图层、画笔、文字、智能对象3.上图层右击选择创建剪贴蒙版,或按住Alt键,在上下图层之间移动,出现方框带箭头形状,单击鼠标左键,或Ctrl+Alt+G 创建/释放4.剪切蒙版可以同时多个图层 进行剪贴蒙版{/card-default}图层蒙版(黑隐藏白显示灰色半透明){card-default label="操作步骤" width=""}1.蒙版颜色表示的意义:黑色:隐藏图像、白色:显示图像、灰色半透明 蒙版只认黑白灰,除了黑白其他颜色都是不同程度的灰2.可以在蒙版上添加颜色的方式:画笔、渐变、填充等3.暂停蒙版使用:按住Shift点击图层蒙版缩览图4.使用蒙版时容易出现的问题:①在使用时出现涂抹颜色的情况,多数是没有添加或选择蒙版缩览图。②在使用蒙版时,涂抹无效果,看下当前前景色是否是白色③在使用蒙版时,涂抹无效果,看下画笔的透明度或流量是否是1%{/card-default}通道{card-default label="操作步骤" width=""}1.作用:用于储存颜色信息,相当于颜色银行2.第一个通道为复合通道,不同的通道会显示不同的颜色信息3.单色通道中黑白灰的意义:白色表示颜色值最高255,黑色0,灰色0-2554.Alpha通道的作用:可以储存和制作选区,黑色非选区,白色选区,灰色半透明选区{/card-default}快捷键整理创建/释放剪贴蒙版 Ctrl+Alt+G 第十一课 打造滤镜下的艺术效果滤镜{card-default label="操作步骤" width=""}1.转换为智能滤镜:可以将普通的位图转为智能对象2.滤镜使用规则:▼ RGB模式下滤镜都可以使用▼ CMYK Lab 模式下有部分滤镜不能使用▼ 索引模式下滤镜不能使用.3.智能滤镜的优点:自带蒙版,可编辑性强,可以对滤镜的效果单独进行多次修改或调整4.上次滤镜操作:快捷键Ctrl+F可以再次执行上次的滤镜操作5.渐隐:快捷键Ctrl+Shift+F 编辑—渐隐 对普通图层滤镜效果再编辑,可以调整不透明度和混合模式(不常用)6.图像中有选区时,滤镜效果只对选区内有效,没有选区时,对整体图像有效7.滤镜库:里面有现成的滤镜效果,可以通过调成参数从而改变滤镜的效果,通过下方新建按钮可以创建多个滤镜效果8.滤镜库—素描:多个滤镜应用前/背景色,亮部应用背景色,暗部应用前景色9.▷ 自适应广角:可较正广角导致的变形图像▷ camera raw滤镜:可以调整图像颜色等▷ 镜头较正:可制作鱼眼镜头拍摄产生的效果,可以对照片的畸变和暗角进行一定程度的矫正▷ 液化:可通过平移、旋转、进行像素变形(瘦身瘦脸等)▷ 消失点:可以通过内置透视网格、进行图像修图(透视:近大远小效果)▷ 模糊系列:可以根据参数对图像进行各种形式整体模糊处理。局部模糊可以通过选框进行控制。▷ 扭曲系列:根据不同方式对图像进行整体像素变形▷ 锐化系列:对图像进行整体边缘对比强化,使图片整体更加清晰。如果参数过大图像会损坏。▷ 杂色:添加杂色:可以添加颗粒杂色▷ 其他滤镜:高反差保留:可以保留细节与叠加柔光一起使用10.渲染—云彩:可以应用没有像素的区域(空白图层),应用的是前/背景色{/card-default}快捷键整理重复上次滤镜 Ctrl+Alt+F低版本重复上次滤镜 Ctrl+F渐隐 Ctrl+Shift+F 第十二课 让我们换一种颜色看世界(调色一)色彩模式{card-default label="操作步骤" width=""}1.RGB:光学三原色,也是调色运用最多的一种颜色模式2.CMYK:印刷用的颜色 青、洋红、黄、黑3.灰度模式:图像不包含颜色,只有黑白灰三种颜色,并影响之后的颜色使用4.去色(Ctrl+Shift+U ):把图像的饱和度降到最低,不影响色彩模式,对于之后的颜色使用没有影响5.更改模式:菜单栏—图像—模式{/card-default}调色{card-default label="操作步骤" width=""}1.调整面板:点击效果,直接新建图层,自带图层蒙版,可以多次调解,只对下方图层起作用2.亮度/对比度:亮度、添加/减少图像明暗程度 对比度、增加/降低图像明暗对比程度3.色相/饱和度Ctrl+U :色相、色彩的相貌 饱和度、颜色鲜艳程度 明度、颜色的明暗程度 单色制作时勾选着色4.三原色:红绿蓝 间色:原色+原色=间色 黄、洋红、青互补色(反色):可以互相抵消的颜色、180°的颜色、相对的颜色三对互补色:红色与青色 蓝色与黄色 绿色与洋红 5.色彩平衡(Ctrl+B ):可以根据颜色的色相来调节6.渐变映射:一般结合混合模式和不透明度来使用 通俗的说就是用你所设定的颜色,对应到原图的色彩上。用这种效果可以达到某些非常夸张的色彩搭配效果。7.可选颜色:对单一颜色进行调整“相对”比较柔和 “绝对”比较犀利 相对运用的较多8.替换颜色:图像—调整—替换颜色 拾取一种颜色,选择另一种颜色替换(可以用添加吸管添加颜色){/card-default}快捷键整理去色 Ctrl+Shift+U 第十三课 从昏暗到光明(调色二)色阶(快捷键Ctrl+L){card-default label="操作步骤" width=""}1.输入色阶——数字图像本来的色阶范围,通过调节改变黑白灰范围输出色阶——是指为打印机指定最小的暗调色阶和最大的高光色阶,调整时调整的是整体的明暗度 2.可以调整图像的阴影、中间调和高光的强度级别,校正色调范围和色彩平衡{/card-default}曲线(快捷键Ctrl+M)它整合了“色阶”、“亮度/对比度”等多个命令的功能。曲线上可以添加14个控点,移动这些控制点可以对色彩和色调进行非常精确的调整a 按Shift 点击可以选中并控制多个控制点b 点击Delete键可以删掉控制点照片滤镜可用于矫正照片的颜色颜色查找查询颜色,形成滤镜效果第十四课 快捷键总结
-
Pandas中文手册 如果你想学习Pandas,建议先看两个网站。(1)官网:Python Data Analysis Library(2)十分钟入门Pandas:10 Minutes to pandas关键缩写和包导入在这个速查手册中,我们使用如下缩写:df:任意的Pandas DataFrame对象s:任意的Pandas Series对象同时我们需要做如下的引入:import pandas as pdimport numpy as np导入数据pd.read_csv(filename):从CSV文件导入数据pd.read_table(filename):从限定分隔符的文本文件导入数据pd.read_excel(filename):从Excel文件导入数据pd.read_sql(query, connection_object):从SQL表/库导入数据pd.read_json(json_string):从JSON格式的字符串导入数据pd.read_html(url):解析URL、字符串或者HTML文件,抽取其中的tables表格pd.read_clipboard():从你的粘贴板获取内容,并传给read_table()pd.DataFrame(dict):从字典对象导入数据,Key是列名,Value是数据导出数据df.to_csv(filename):导出数据到CSV文件df.to_excel(filename):导出数据到Excel文件df.to_sql(table_name, connection_object):导出数据到SQL表df.to_json(filename):以Json格式导出数据到文本文件创建测试对象pd.DataFrame(np.random.rand(20,5)):创建20行5列的随机数组成的DataFrame对象pd.Series(my_list):从可迭代对象my_list创建一个Series对象df.index = pd.date_range('1900/1/30', periods=df.shape[0]):增加一个日期索引查看、检查数据df.head(n):查看DataFrame对象的前n行df.tail(n):查看DataFrame对象的最后n行df.shape():查看行数和列数http://df.info():查看索引、数据类型和内存信息df.describe():查看数值型列的汇总统计s.value_counts(dropna=False):查看Series对象的唯一值和计数df.apply(pd.Series.value_counts):查看DataFrame对象中每一列的唯一值和计数数据选取df[col]:根据列名,并以Series的形式返回列df[[col1, col2]]:以DataFrame形式返回多列s.iloc[0]:按位置选取数据s.loc['index_one']:按索引选取数据df.iloc[0,:]:返回第一行df.iloc[0,0]:返回第一列的第一个元素数据清理df.columns = ['a','b','c']:重命名列名pd.isnull():检查DataFrame对象中的空值,并返回一个Boolean数组pd.notnull():检查DataFrame对象中的非空值,并返回一个Boolean数组df.dropna():删除所有包含空值的行df.dropna(axis=1):删除所有包含空值的列df.dropna(axis=1,thresh=n):删除所有小于n个非空值的行df.fillna(x):用x替换DataFrame对象中所有的空值s.astype(float):将Series中的数据类型更改为float类型s.replace(1,'one'):用‘one’代替所有等于1的值s.replace([1,3],['one','three']):用'one'代替1,用'three'代替3df.rename(columns=lambda x: x + 1):批量更改列名df.rename(columns={'old_name': 'new_ name'}):选择性更改列名df.set_index('column_one'):更改索引列df.rename(index=lambda x: x + 1):批量重命名索引数据处理:Filter 、Sort 和 GroupBydf[df[col] > 0.5]:选择col列的值大于0.5的行df.sort_values(col1):按照列col1排序数据,默认升序排列df.sort_values(col2, ascending=False):按照列col1降序排列数据df.sort_values([col1,col2], ascending=[True,False]):先按列col1升序排列,后按col2降序排列数据df.groupby(col):返回一个按列col进行分组的Groupby对象df.groupby([col1,col2]):返回一个按多列进行分组的Groupby对象df.groupby(col1)[col2]:返回按列col1进行分组后,列col2的均值df.pivot_table(index=col1, values=[col2,col3], aggfunc=max):创建一个按列col1进行分组,并计算col2和col3的最大值的数据透视表df.groupby(col1).agg(np.mean):返回按列col1分组的所有列的均值data.apply(np.mean):对DataFrame中的每一列应用函数np.meandata.apply(np.max,axis=1):对DataFrame中的每一行应用函数np.max数据合并df1.append(df2):将df2中的行添加到df1的尾部df.concat([df1, df2],axis=1):将df2中的列添加到df1的尾部df1.join(df2,on=col1,how='inner'):对df1的列和df2的列执行SQL形式的join数据统计df.describe():查看数据值列的汇总统计df.mean():返回所有列的均值df.corr():返回列与列之间的相关系数df.count():返回每一列中的非空值的个数df.max():返回每一列的最大值df.min():返回每一列的最小值df.median():返回每一列的中位数df.std():返回每一列的标准差
-